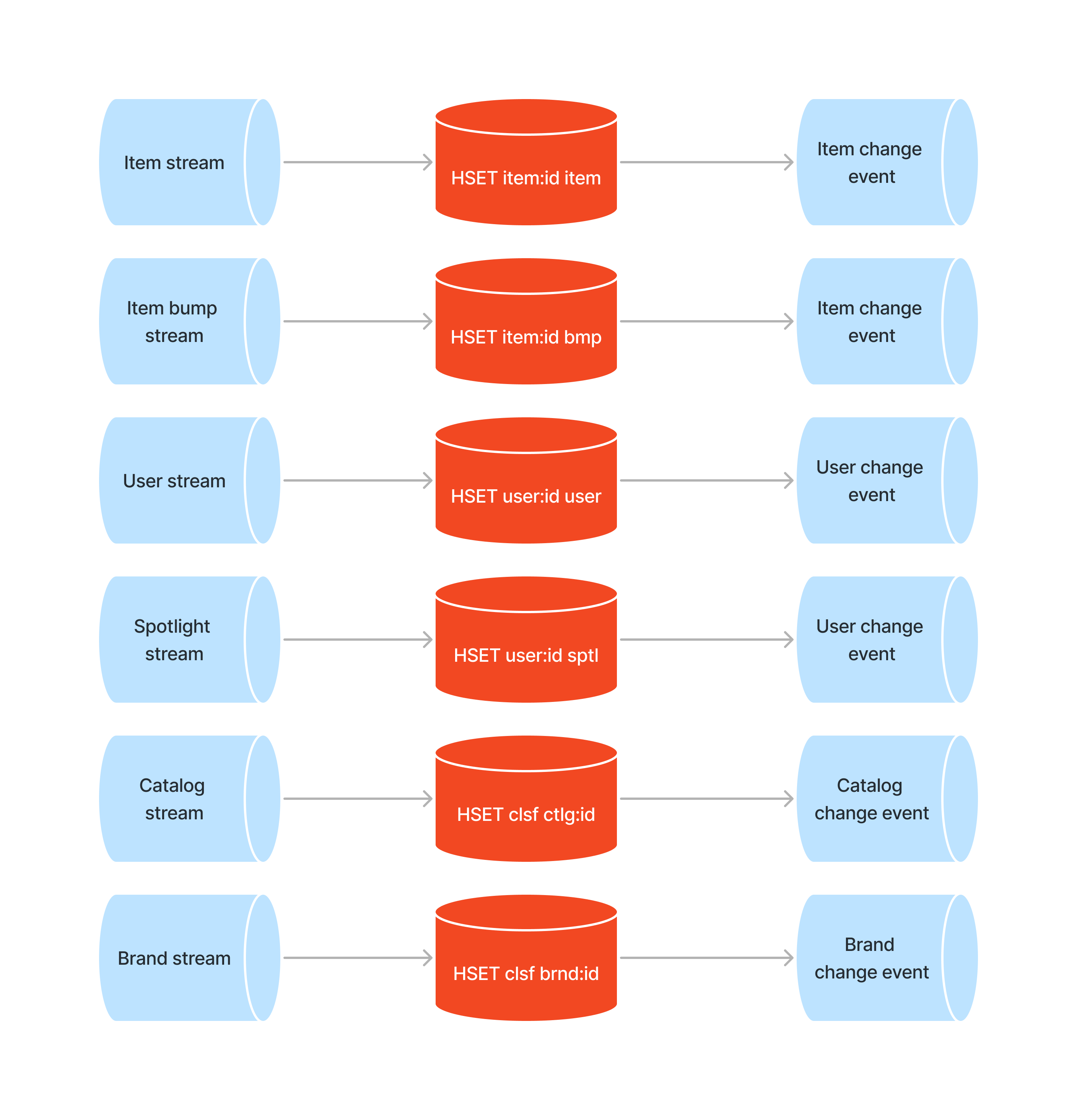
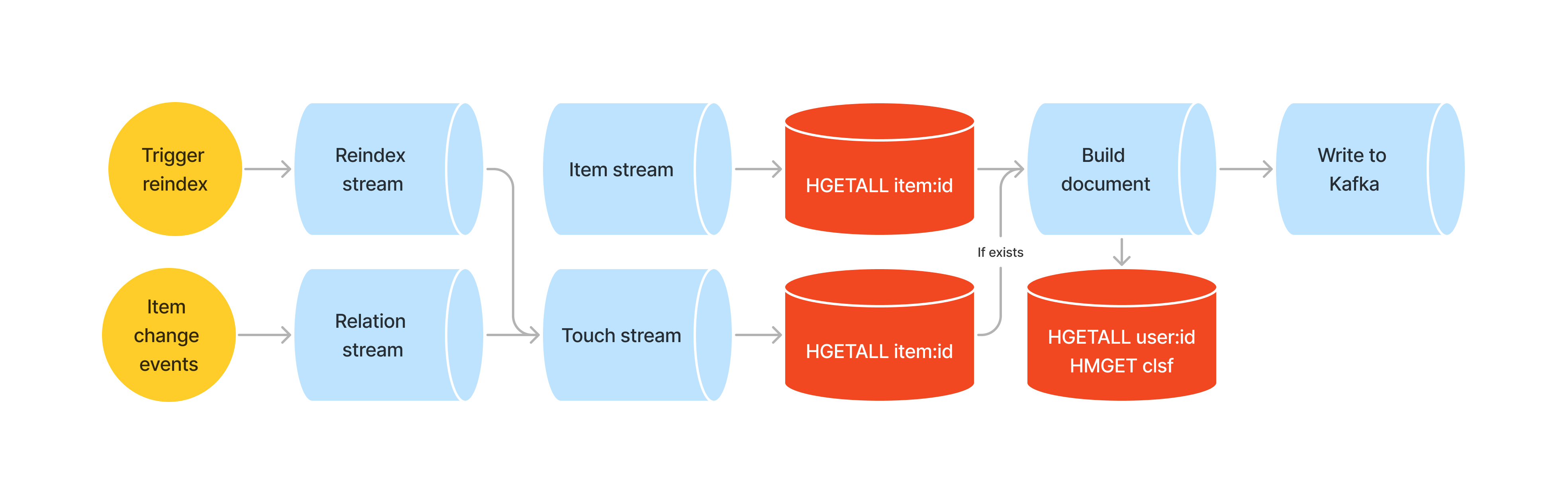
At Vinted, we’ve implemented a 3-stage recommender system that leverages both explicit and implicit user preferences to offer users a curated list of items presented on the homepage. Explicit preferences are inputted by users on the app, allowing them to specify details such as the clothing sizes they are interested in. Meanwhile, implicit preferences are extracted from historical user interactions on the platform, including clicks and purchases, via the use of machine learning models. This system distills a tailored selection from millions of available listings, presenting users with options most aligned with their tastes and behaviors.
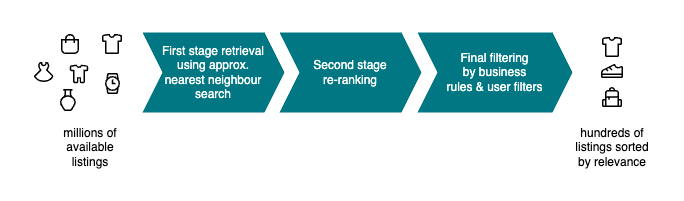
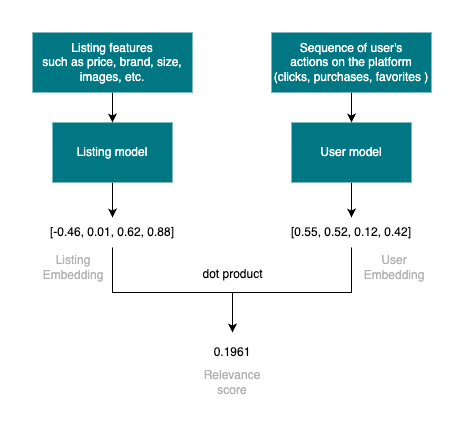
The goal of the first stage of the system is to quickly ( < 100 ms ) recall the most relevant content based on historical user behavior. This is done by utilizing the approximate nearest neighbor (ANN) search with embeddings obtained from an in-house two-tower recommendation model. The listing “tower” of this model is responsible for generating vector representations of listings based on various metadata such as brand, price, size as well as other unstructured data such as photos. The second “tower” is responsible for generating embeddings of user’s preferences characterized by a sequence of past interactions (clicks, favorites & purchases) with listings on the platform. The model is trained in such a way that the distance between a user’s and listing’s embedding represents the affinity or relevance for the given user-item pair. This score can then be used to rank listings based on relevance for a given user and select a smaller list of candidates for the next stage.
When implementing the first iteration of this system we have chosen to use the Facebook AI Similarity Search (Faiss) library for performing ANN searches. While Faiss served us well in the first iterations of this system to prove value, it is not a complete database solution, and we found the following drawbacks:
- We used Faiss as a read-only index in a stateless Kubernetes service that would have to be periodically rebuilt and redeployed to include newly uploaded items and remove sold or deleted content.
- Faiss has no capability for approximate nearest neighbor searches with pre-filtering based on metadata. You can only retrieve the top-k scoring items from this index, and any filtering would have to be performed as a post-processing step on the fixed-length list of retrieved items. This was especially problematic for us, as our product allows users to specify custom filters. Therefore, if the top-scoring items retrieved did not pass these filters, our users would see no recommendations at all.
So we set out in search of a database system that would take care of managing the data and indices, as well as allow us to filter items based on metadata such as brand, size, and so on such that we could always retrieve recommendations for our users, no matter what filters they have set.
In search for a vector search database
As alternative technologies that could satisfy the constraints mentioned above, in the summer of 2022, we’ve evaluated Vespa and Elasticsearch. More systems that support ANN with prefiltering were researched but eventually rejected either because of licensing concerns ( Vinted prefers truly open-source licensed software ) or due to overall lack of maturity of the project.
Vespa
Vespa is an application platform for low-latency computations over large datasets. It is used to solve problems such as search, vector search, real-time recommendation, personalization, ad targeting, etc. The platform is open source under the Apache 2.0 license. One particular aspect that drew us to Vespa was its first-class support for machine learning based search and ranking. On top of that, the real-time data update capability is appealing. The main complicating factor for adoption was that Vinted had no experience with Vespa.
Elasticsearch
Elasticsearch is a mature and popular system for search and analytics use cases. Elasticsearch is built on top of the Lucene library. The seemingly endless list of features makes it a trusty and future-proof technology. Elasticsearch supports ANN with prefiltering from version 8.0.
Even though the license is not open-source, Elasticsearch was a strong contender because Vinted was already using it for search and had solid engineering competencies to operate it at scale.
Benchmarking
To understand how these technologies would perform for our use case, we implemented benchmarks using real data. The goal of these benchmarks was to measure peak document indexing throughput as well as query throughput and latency.
Setup
Benchmarks were performed on a single Google Cloud Platform n1-standard-64 VM instance (64 vCPUs, 236 GB). The dataset consisted of ~1M documents, each document contained 12 fields and a 256 dimension float32 embedding. Both Elasticsearch (8.2.2) and Vespa (8.17.19) were deployed as Docker containers, and we’ve made sure to keep the ANN index (HNSW) hyperparameters consistent across both platforms for a fair comparison.
Results
In our benchmarks, we found that Vespa had a 3.8x higher document indexing throughput. Furthermore, querying benchmarks have shown that Vespa was able to handle 8x more RPS before saturating the CPU, and at this throughput had a P99 latency of 26ms. Elasticsearch, even at just 250 RPS had a P99 latency of 110ms (4.23 times higher).
Of course, if the benchmarks were run today with up-to-date versions then the numbers would be different.
Given these results, we have decided to move forward with setting up Vespa for an AB test.
System setup
Having the numbers from the load testing, we’ve estimated that to achieve high-availability (HA), 3 servers with 56 CPU cores each were needed to handle the expected load for the AB test. Deploying Vespa was as easy as setting an environment variable
VESPA_CONFIGSERVERS=server1.vinted.com,server2.vinted.com,server3.vinted.com
and then running a Docker container with Vespa on each server.
The application package was mostly the same as the one used for the load testing. The only change was that we’ve set up the content cluster with 3 groups. That made each server store a complete copy of the dataset and having more groups helped to scale the query throughput.
Operations
We’ve found that Vespa is generally easy to operate. One reason is that after the initial setup there is no need to touch the running servers: all the configuration is controlled by deploying the application package. On top of that, Vespa out-of-the-box exposes an extensive set of metrics in Prometheus format that makes creating detailed Grafana dashboards an easy task.
We consider the performance to be good enough: the P99 latency of first stage retrieval handled by Vespa is around ~50 ms. However, there was a small portion of problematic queries that took much longer to execute than the set query timeout of 150ms. Vespa has an excellent tool for debugging problematic queries: tracing. With the hints from the traces, we’ve sought help in the Vespa Slack which led to a GitHub issue. The Vespa team was quick to respond and fixed the root cause of the issue in subsequent Vespa releases. So far so good.
Approximate Search vs Exact Search
As mentioned previously, the first-stage of our recommendation system utilizes an approximate nearest neighbor search algorithm to balance the trade-off between accuracy and speed. When dealing with large datasets, finding exact nearest neighbors can be computationally expensive, as it requires a linear scan across the entire corpus. Approximate search algorithms such as HNSW aim to find neighbors that are “close enough”, which makes the search faster at the cost of accuracy. Additionally, ANN search algorithms often allow for fine tuning of the accuracy vs speed trade-off via parameters such as the “max-links-per-node”.
We were curious to quantify exactly how much accuracy was traded off by our choice of the HNSW parameters we’ve set in our Vespa deployment. Initially, we started by measuring recall - the proportion of matching documents retrieved between approximate and exact searches. We’ve found that with our choice of parameters the recall was around 60-70%. However, visually the retrieved results and scores were very similar, and we were wondering if our users could perceive this difference and if that difference would affect their engagement and satisfaction. To test this hypothesis, we performed an AB test where half of our users received recommendations retrieved using approximate search, and the other half received exact search results.
To accommodate such an experiment we needed some spare hardware resources. Luckily, we’ve recently set up a bigger Vespa deployment and until other features were deployed the resources were readily available. When it comes to Vespa, it is easy to switch from ANN to exact search just by changing a query parameter, i.e. approximate:true was changed to approximate:false, e.g.
select * from doc where {targetHits: 100, approximate:true}nearestNeighbor(user_embeddings)
// to
select * from doc where {targetHits: 100, approximate:false}nearestNeighbor(user_embeddings)
The change in algorithm caused the latency at P99 to jump from a stable ~50ms to a more bumpy ~70ms (+40%).
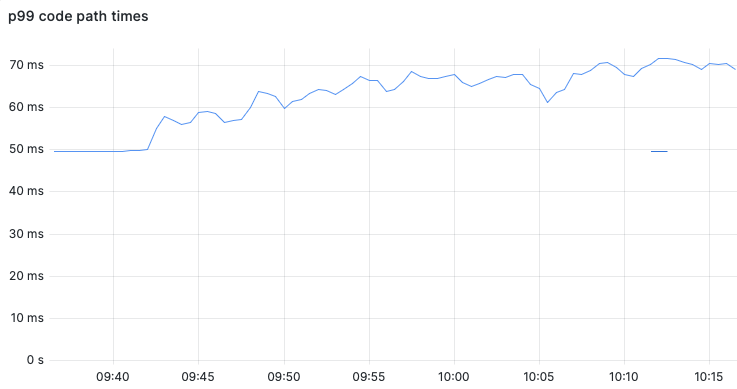
The CPU load on Vespa search nodes increased slightly, however, we found that the user satisfaction with the exact search had not increased enough to justify the higher resource usage and query latency.
Member testimonies
The implementation of our recommender system on Vespa was a pleasant experience from an engineering point of view. While we were able to measure increased member satisfaction via a sequence of AB tests along the way, we were pleasantly surprised to hear member feedback about improvements that we were able to deliver by utilizing the new capabilities provided by Vespa:
I don’t know why I hadn’t looked at this or used this before as much as I do now.
Actually, Vinted is I think the only app that I use to just browse the main page because the stuff that comes up there is personalized to the user and based probably on my recent searches and recent buys and finds.
I’ve recently found that I do find myself overnight time scrolling through. Actually, the matches are pretty good, you know, often where I put quite a lot of stuff in my favorites by just looking at that.
A cherry on top is when we hear anecdotal feedback from random people mentioning that they only use the recommendations feature on Vinted because for them it seems that Vinted has a better understanding of their taste now.
Summary and future work
By leveraging ANN with prefiltering we’ve significantly improved the relevance of recommendations on our homepage. Also, the broader adoption of Vespa for item recommendation use cases enables numerous other product improvements and paves the way to simplify our system architecture.
Our team is excited about what we’ve achieved so far, and we can’t wait until we release new features for Vinted members that leverage the blend of dense and sparse retrieval techniques. Stay tuned!
]]>