Teaching the Old Dog a New Trick
TL:DR: When required data can be encoded with match-features, Vespa can apply a new optimisation, which can be a lifesaver when data is frequently redistributed.
Use-case
When ranking, Vespa requires additional information that cannot be easily stored within the documents being ranked (e.g. the statistical cross features between the user and the document such as a counter of how many interactions the user has made with the documents of this category can’t be stored within an item itself). Then, you need to pass them as parameters via ranking features. An important question is: where do you store and fetch that information from?
When Redis became a bottleneck for this task, we decided to try Vespa itself. Why?
- The data format is already suitable because it is going to be passed into the ranking profile.
- It becomes possible to eliminate some network round-trips.
- Vespa is scalable to any dataset size and can store data both in memory and on disk.
- Vespa allows for fetching multiple filtered documents.
- Vespa allows for collocating calculations with the data.
And of course, such tasks require single-digit millisecond latency.
Problem
Initially, the use e of Vespa for use cases worked well, and looked like a great success. However, the proverbial honeymoon ended when the number of schemas (50+) and the update rate (500M+ per hour) skyrocketed. We noticed that sometimes tail (p99+) latencies bumped to 100ms+, seemingly out of nowhere, but the bump sometimes correlated with the high feeding bursts (meaning right after the feeding burst). Such high latencies are unacceptable when the latency budget is 50 ms.
Investigation
We noticed that the spike in tail latencies always happened after a burst of feeding requests. E.g. features that are recalculated hourly/daily for all Vinted users (i.e. 100+ million records) create such bursts. When latencies started spiking more and more frequently, it was a signal to have a closer look to see what the cause was.
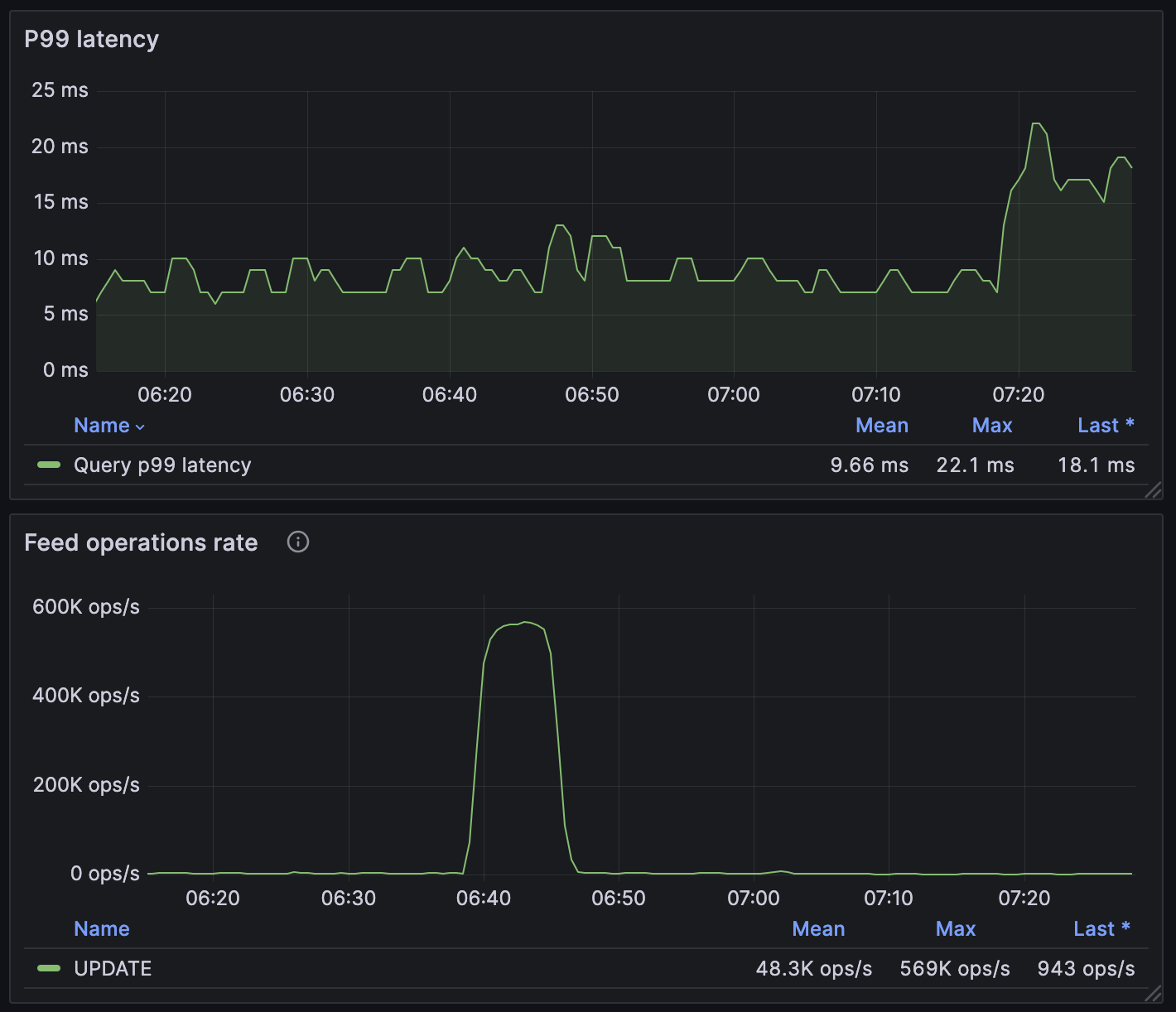
The diagram above shows that a spike in p99 latency occurred after a feeding burst.
After inspecting the logs during such a latency spike, there were multiple records such as the following:
Docsum fetch failed for 36 hits (64 ok hits), no retry
The log says that some document summaries have failed.
After a guru meditation session at the Vilnius office sauna (which is intended for such type of work), we concluded that the data is moving around the cluster and it causes problems for document summary fetching.
This theory was quickly confirmed by checking the dashboard on data redistribution.
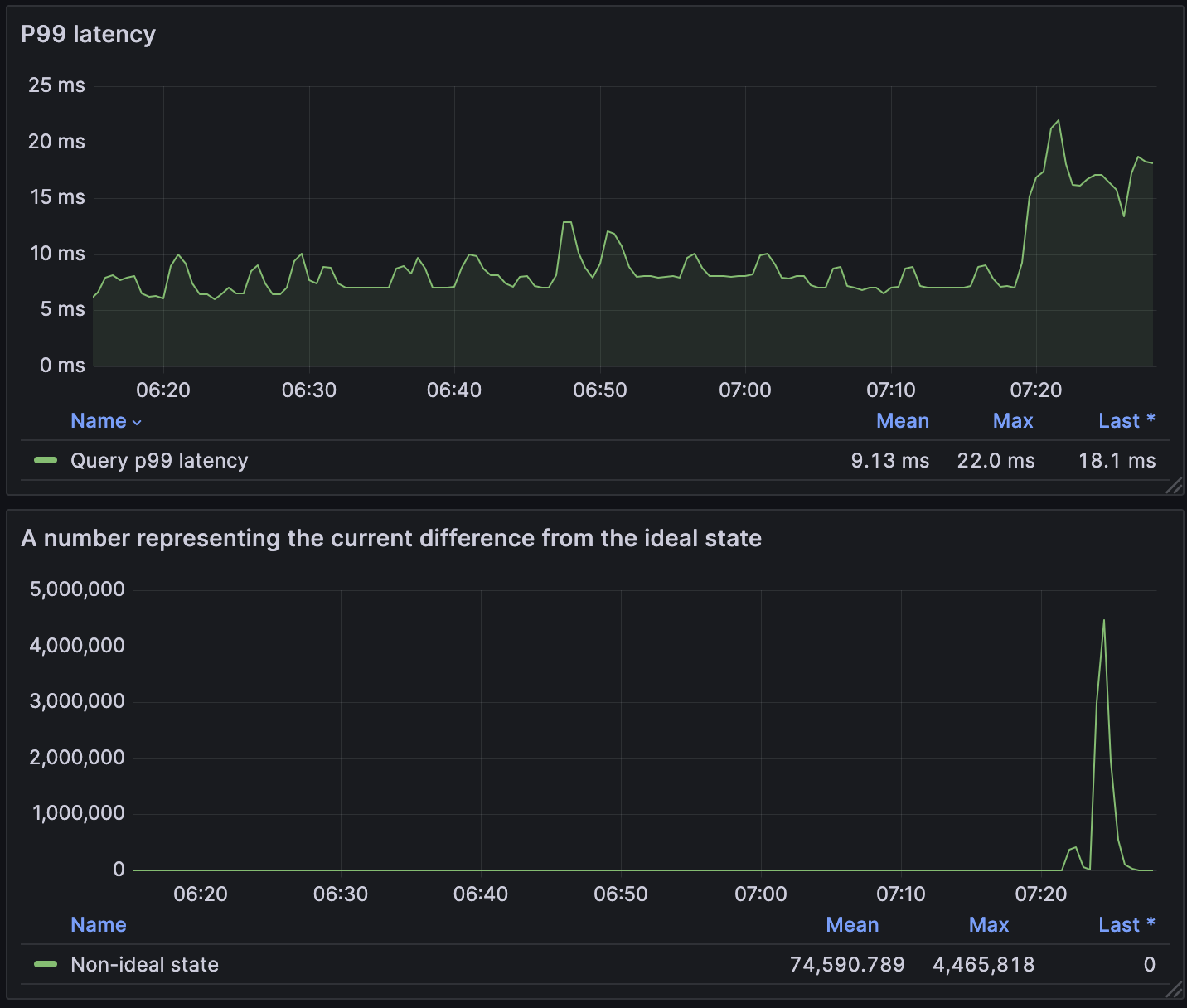
With this evidence, the problem to solve was clear but first, we need to familiarise ourselves with how Vespa executes queries.
Query Execution
This is the typical query execution flow:
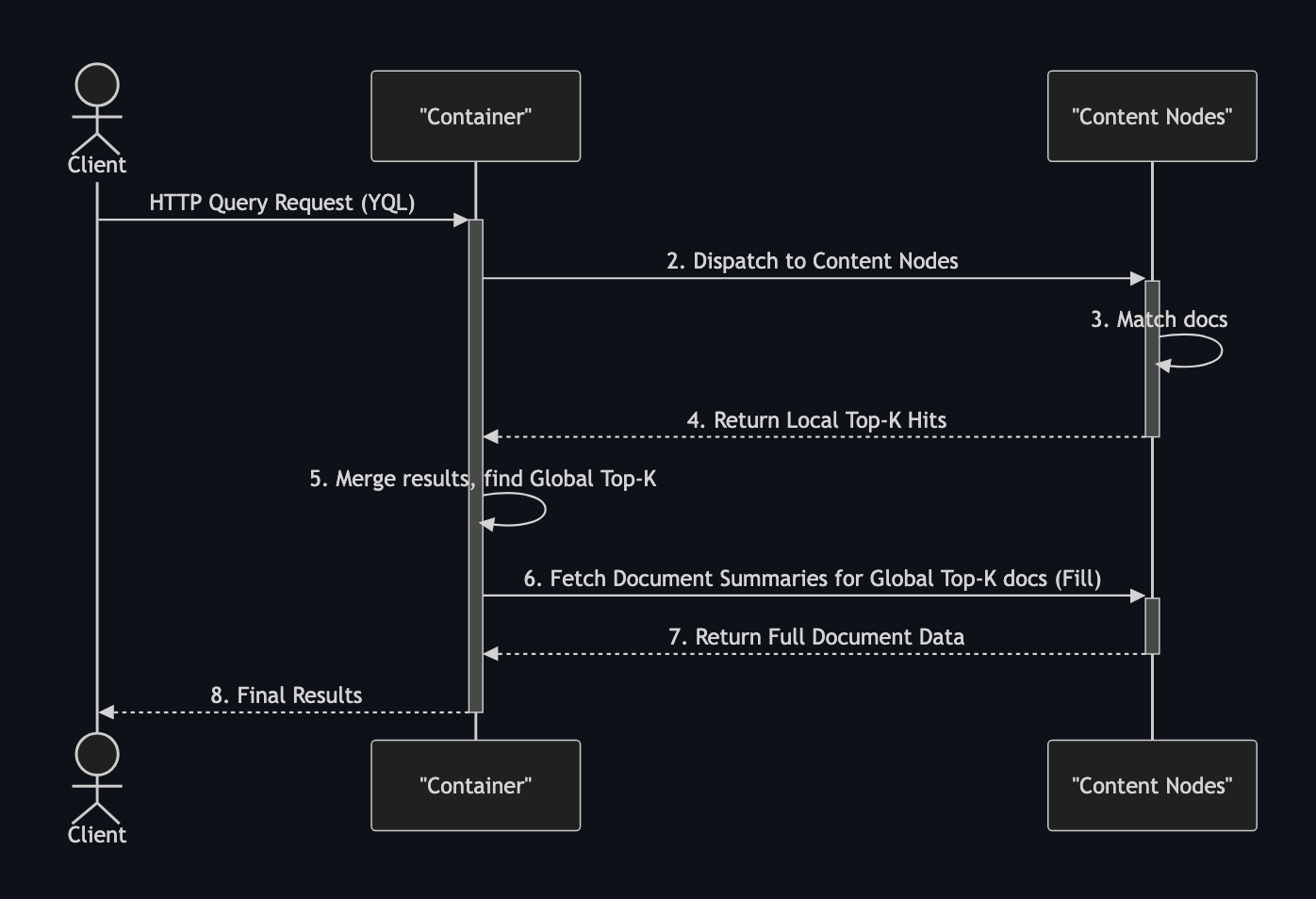
The diagram above shows that a request first comes to the Vespa container node. Then, it is scattered to all content nodes (typically over the network) of an available content group. Responses with local Top-K hits are then gathered in the container node. The Top-K global matching documents a .fill() request is once again sent to the relevant content nodes to fetch the document summary (i.e. document data or calculated values).
When a data redistribution is ongoing during the query handling, it might happen that between the query execution and .fill() (that typically takes a couple of milliseconds), the documents is moved from one content node to another (or the content node is down, or some other unexpected situation that happens in distributed systems). To handle such a situation, Vespa queries all known content nodes for the summary data, potentially doing multiple retries.
Typically, summary fetching takes ~1 ms, but we’ve seen summary fetching taking ~100 ms.
A small nuance to note about the query execution flow is that, with the first response from content nodes, the matchfeatures can be returned.
Match features are rank features, added to each hit into the matchfeatures field. The feature was added to Vespa in 2021. The values can be either floating point numbers or tensors (but not strings, booleans, etc.). Typically, they are useful to record the feature values used in scoring for further ranking optimisation.
A clever trick to encode non-numeric data, e.g. a string label, is to convert it into a mapped tensor. If you squint a little, the mapped tensor looks like a regular JSON object.
Solution
By knowing the problem and being familiar with matchfeatures, we can draft a workaround for summary fetching.
Luckily, we’ve already thought about such an optimisation! What if everything we needed could be fetched with the select match-features from …? Summary fetching would then not be required, and .fill() could be eliminated.
The enthusiasm led to a quick proof of concept; however, the benchmarks surprisingly showed no improvement at all. This led to an inspection of the query trace, in which we found that the summary was being fetched! This was confirmed with the metrics on the Vespa side, on docsum operations.
It was high time to roll up our sleeves and do some open source work. The feature was released with Vespa 8.596.7.
Open source contributions take time (review, accept, release, adopt cycle can take weeks), but we needed the solution quickly Vespa is extremely flexible, and we could alter the platform ourselves with aplugin by adding your bundle JAR file into the components/ directory, and configuring the search chain.
Let’s explore the Vespa application setup. First, we need to create a rank profile that encodes data into tensors.
schema doc {
document doc {
field my_feature type string {
indexing: attribute
}
}
rank-profile fields inherits unranked {
function my_feature() {
expression: tensorFromLabels(attribute(my_feature))
}
match-features {
my_feature
}
}
}
Then, we need to specify the fields rank profile when querying. As a bonus, we can disable the query cache, because it helps during the summary fetching and asks for the short version of tensors:
{
"yql": "select matchfeatures from doc where true",
"ranking": "fields",
"ranking.queryCache": false,
"presentation.format.tensors": "short-value"
}
The response looks like:
{'root': {
'id': 'toplevel',
'relevance': 1.0,
'fields': {'totalCount': 1},
'coverage': {
'coverage': 100,
'documents': 1,
'full': True,
'nodes': 1,
'results': 1,
'resultsFull': 1},
'children': [{
'id': 'index:content/0/c4ca42388ce70a10b392b401',
'relevance': 0.0,
'source': 'doc,
'fields': {
'matchfeatures': {
'my_feature': {
'MY_LABEL_VALUE': 1.0
}
}
}
}]
}
Third, the match-features need to be converted into a usable form. That is, either in a custom searcher, or in your application.
Without summary fetching, the query execution is much simpler.
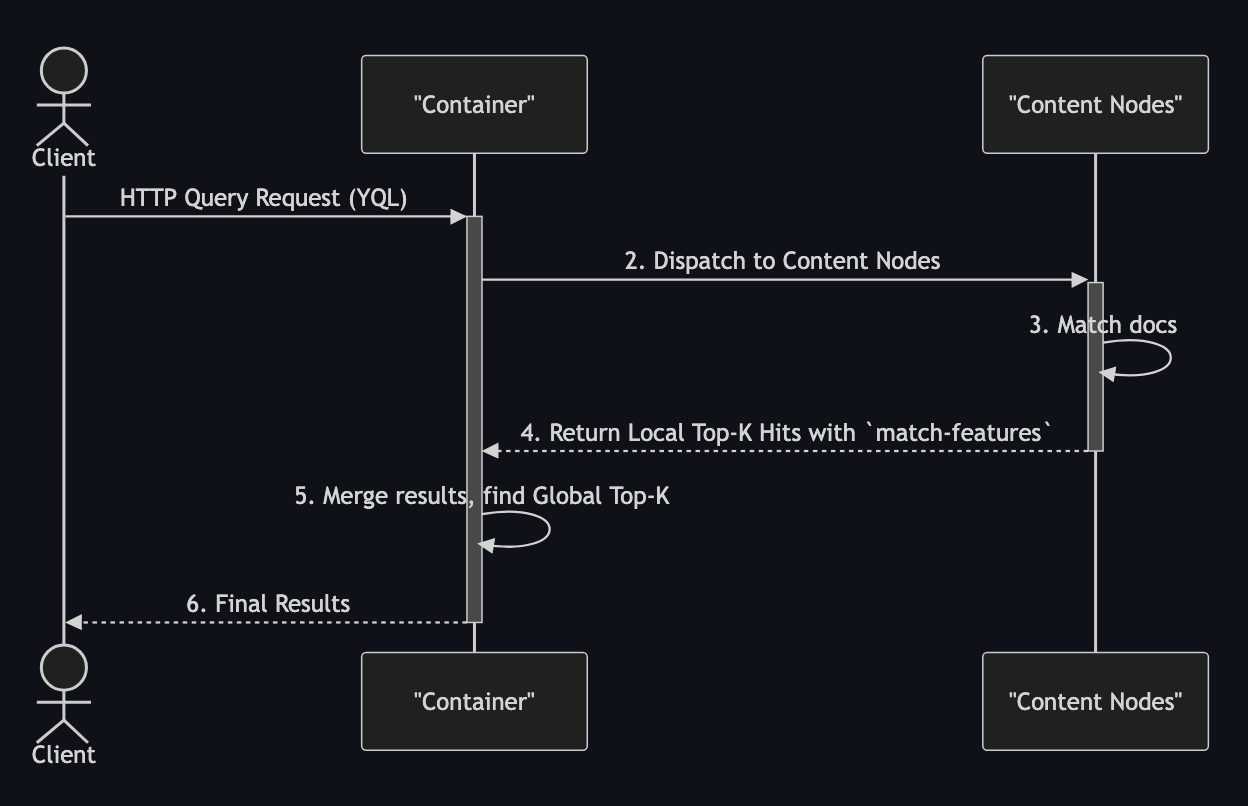
In the diagram above, one network round-trip is eliminated when compared to the typical query execution. Also, this eliminates all the potential summary fetching problems because documents are findable even during data redistributions.
Results
When the solution was deployed, we immediately noticed a drop in tail latencies. But the most important thing was that there were no more latency spikes during data redistribution!
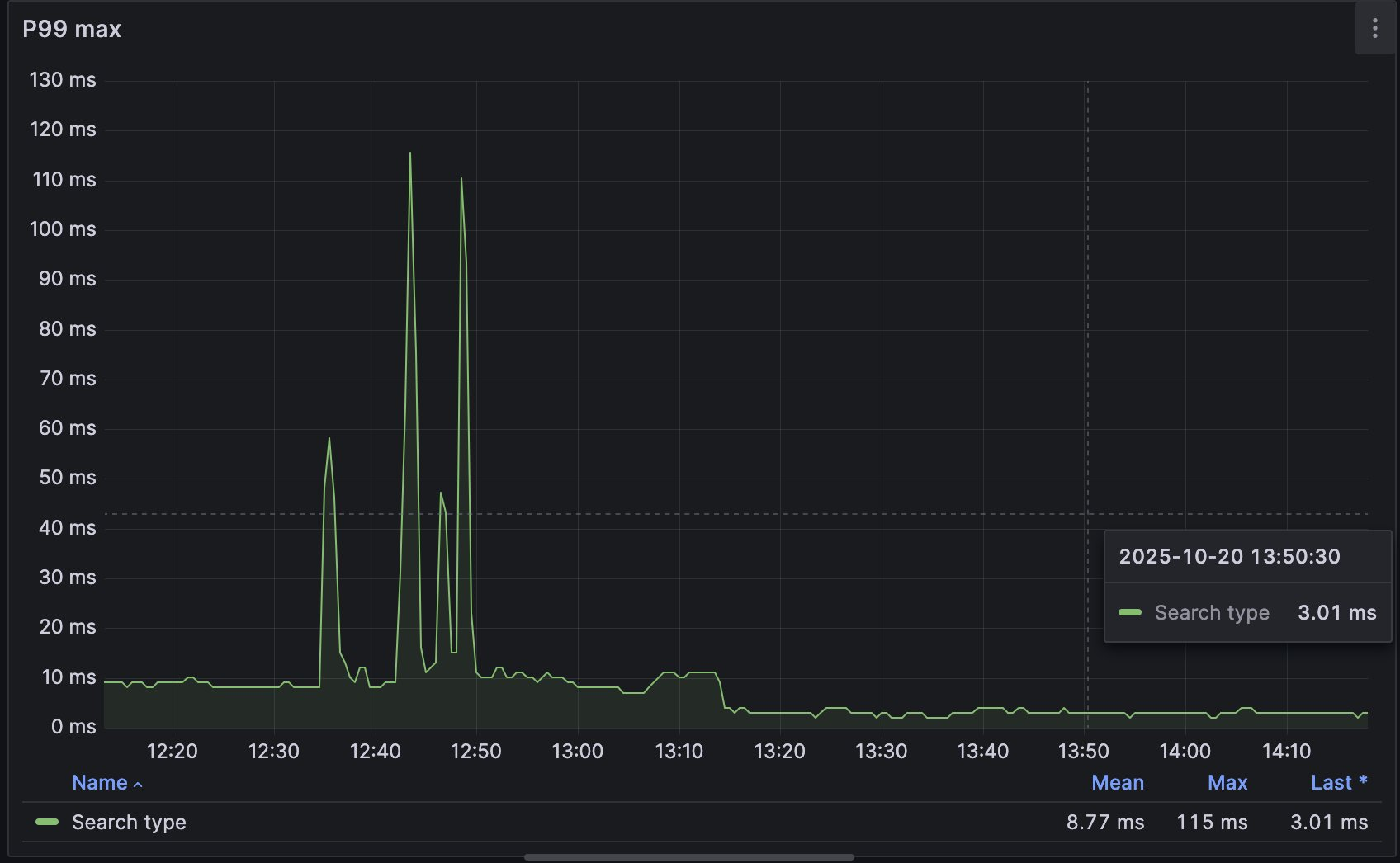
When the change was deployed, the p99 latencies dropped from ~9 ms to about 3 ms. And the latency spikes are gone.
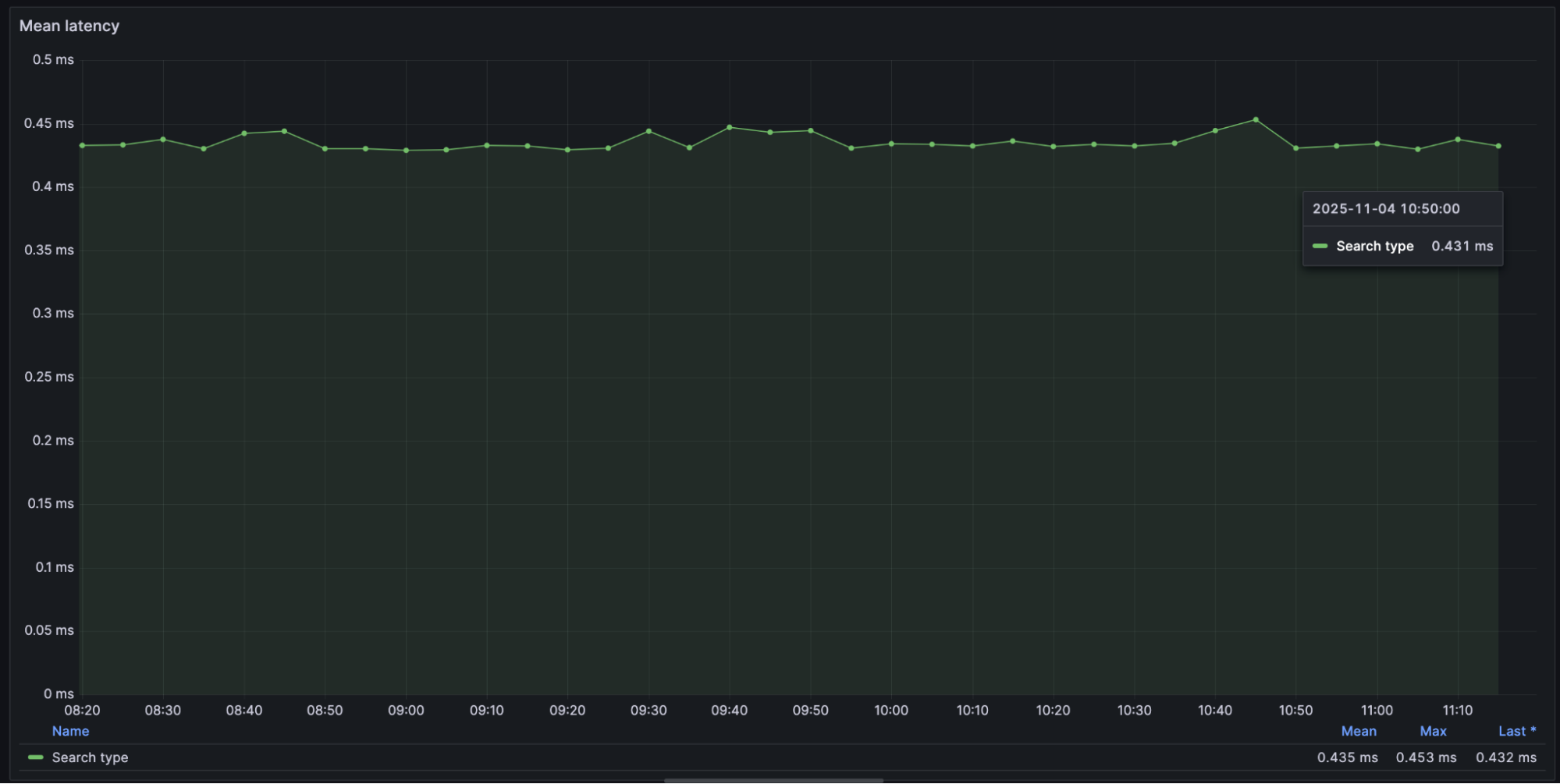
Currently, the mean query latency with ~7.5k RPS per container node is around 430 microseconds.
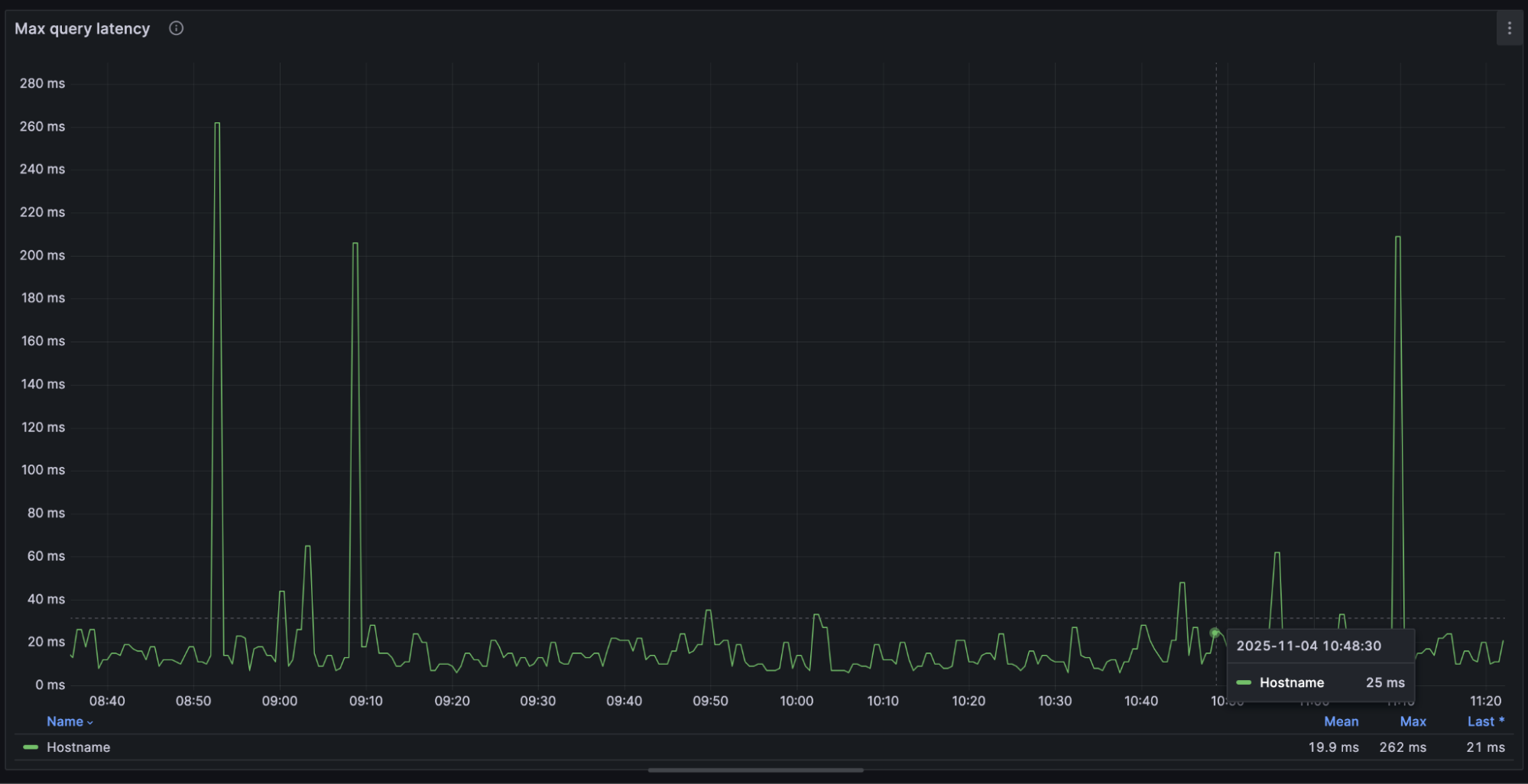
The max latencies (pro tip: always monitor max latencies) are typically ~20 ms. Those ~200 ms spikes are due to packet loss in the network layer (not Vespa specifics).
Discussion
Even though the optimisation is nice, the journey is not yet finished. There are other ways to get even more out of Vespa. Here are several ideas:
- The current implementation creates tensors from attributes at query time. They could be precalculated during indexing.
- The current implementation is usable when querying one schema. For multi-schema support, you either have to encode the datatype name in the document attributes or ask Vespa to add
sddocnameto the response. However, havingsddocnameis filled only on receiving the summary. - A custom renderer could be implemented that serialises data based on the schema into a binary format, avoiding JSON serialisation.
Summary
This new trick of selecting only the matchfeatures in Vespa 8.596.7, helps eliminate not only a network round-trip, but also problems and latencies associated with summary fetching. The overhead of converting attributes into tensors and transmitting slightly more data over the network in our setup was negligible. Of course, this optimisation is not a silver-bullet for all use cases, but when summary fetching is problematic, it really helps.
Kudos to the team for this great work! And thanks to everyone who helped!
P.S.
A fun fact is that the initial hypothesis for latency spikes was the pauses of the JVM garbage collector. However, after setting up the generational ZGC the latency spikes were still there. Garbage collector is almost never a root cause.