Building a Global, Event-Driven Platform: Our Ongoing Journey, Part 1
A few years ago, our platform reached a point where the way we’d always built software simply wasn’t enough anymore. The monolith that powered our early success had served us well, but as the business expanded across the continent, it started showing real limits. Global growth forced us to confront problems we couldn’t ignore: latency across regions, unpredictable load patterns, and an architecture that didn’t match the scale of the company. We needed to rethink how the entire system worked, from the shape of our data to the boundaries between teams.

What follows is the story of that shift - and why the most interesting engineering challenges are still ahead of us.
The Moment Growth Outpaced the Monolith
Many of us grew up professionally inside the monolith. Everything lived in one place. Data was easy to reach. Consistency was immediate. Debugging meant reading a single flow and knowing exactly where things went wrong.
In the mid 2020, as our traffic increased to 150k requests per second in peak hours, that simplicity turned into a constraint. Some endpoints triggered hundreds of database queries. Others spanned dozens of logical databases. Latency between regions created unpredictable behavior. The entire platform lived inside one large failure domain, which meant any issue could cascade much further than it should.
The monolith didn’t just slow us down - it held us back from being truly global.
Discovering the Shape of the System
Our first step wasn’t to break the monolith apart. It was to understand it. A few engineers introduced Domain-Driven Design as a way to map responsibilities and expose natural boundaries inside the application. This quickly became more than a technical exercise. It gave teams clarity about what they owned. It highlighted places where responsibilities were tangled together. It made development faster simply because people weren’t stepping on each other’s toes anymore. Eventually, it guided how we restructured teams and how we planned the future of the architecture.
DDD didn’t give us all the answers, but it gave us the vocabulary to find them.
Moving from Synchronous Calls to Events and Sagas
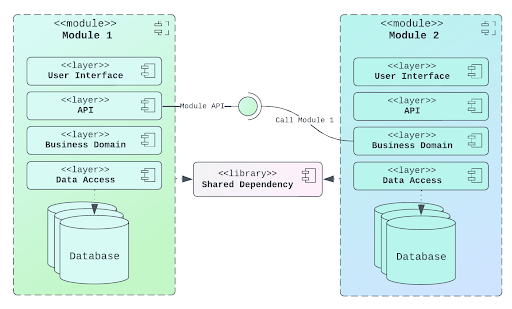
It took us at least two years to understand the domains, as we identified almost 300 of them. But once we understood the domains, another problem became obvious: the entire system relied on synchronous communication. And while that worked fine in a single region, it didn’t survive real-world distributed conditions.
Every synchronous call added latency. Every tight integration increased fragility. And any workflow that needed data across regions suffered from unpredictable delays.
Shifting to business events changed that. Instead of expecting a remote service to respond in real time, services could publish state changes and let other domains react whenever they were ready.
For multi-step workflows, we are introducing Saga-style orchestration. Instead of trying to fake distributed transactions, we are embracing compensations, retries, and eventual completion. These ideas required new habits, new coding patterns, and a new mindset - but they let us operate reliably across geographic boundaries.
This was the moment the platform started to behave more like a distributed system and less like a stretched monolith.
In the next part, we will move from why the architecture had to change to how it operates at a global scale. We will look at the concrete decisions behind our multi-region model, why we centralized writes while distributing reads, and how events and projections make that possible. This is where the platform stops being just distributed in theory and starts delivering predictable performance worldwide.