Building a Global, Event-Driven Platform: Our Ongoing Journey, Part 2
In the first part, we described how growth pushed us beyond the limits of the monolith and forced us to rethink our architecture from the ground up. We explored how Domain Driven Design helped us uncover clear boundaries, and how shifting from synchronous calls to events and sagas changed the way the system behaves under real distributed conditions. With that foundation in place, we can now focus on what it takes to run this platform reliably across continents.
Designing for a Global Footprint
Operating across continents forces you to rethink even the assumptions that once felt foundational. One of the biggest decisions we made was choosing not to shard our primary data models across regions. Instead, we embraced a model where all writes happen in the primary site and read-only projections are replicated around the world. This gives us a single source of truth for writes while still providing fast, local reads to users regardless of geography.
It wasn’t an easy choice. It meant accepting that global consistency would always lag by at least a few moments and that network behavior would play a real role in how fresh data appears in different regions. But it also avoided the complexity and operational cost of a fully sharded, multi-writer system - complexity that becomes hard to justify unless the business absolutely demands it.
What this approach gave us, though, was predictable behavior under load. We started building our projections to tolerate replication delays, survive partial failures, and recover automatically when regions fall behind. Most importantly, we are learning to evaluate every domain and feature through a new lens: how does its read path behave globally, how sensitive is it to freshness, and what happens when the network isn’t cooperating?
Today, this model allows us to serve hundreds of thousands of requests per second worldwide while keeping write logic centralized and robust. Eventual consistency is being built into how the system works, not an edge case we try to hide. And that clarity is making our platform both more resilient and easier to evolve as we plan to expand to more regions.
Faster Reads Through Data Projections
One of the biggest improvements came from separating how we write data from how we read it. Features like feeds, search, and listing pages need fast, region-local access. Depending on remote services simply isn’t an option once you operate across continents.
The answer was to build read-optimized data projections generated directly from our event streams. Each team could decide what their projection looked like, how it should be optimized, and where it should live geographically. This reduced cross-team dependencies and made performance far more predictable.
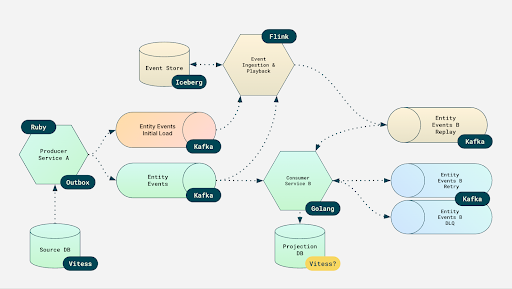
Through the mid of 2026, the projections should power many of our most visible features. They’re a key part of our strategy for low latency and global scale.
The Cultural Shift Behind the Architecture
None of this would have been possible if we hadn’t shifted how teams think about building software. The monolith encouraged a mindset where consistency was free, and data lived everywhere. Distributed systems demand the opposite. And we are talking about ~50 teams.
Teams learned to design for retries, compensations, idempotency, and partial failure. They had to build experiences that hold together even when some events arrive late or in a different order than expected. And perhaps most importantly, they had to take real ownership of domain behavior from end to end and not just code paths.
Conversations changed. Instead of debating individual endpoints, teams talk about flows, boundaries, event lifecycles, data freshness, and recovery. This shift has made our architecture stronger, and it has made our engineering culture stronger too.
Where We Are, and What’s Next
We are now ready to run a hybrid architecture built around services, events, and globally replicated projections. The foundations are in place, but we’re very much in the middle of the journey. A significant part of our work today is focused on strengthening the platform itself: improving our async tooling, defining clear standards for how projections and consumers should be built, and making sure our infrastructure can sustain the traffic patterns we’re seeing — and the ones we know are coming.
We’re still refining the rules for how events flow through the system, how projections handle late or conflicting updates, and how consumers recover after interruptions. A lot of energy is going into making the development experience smoother: better local tooling, more predictable event schemas, cleaner testing patterns, and clearer guidelines for how domains should emit and react to events. At the same time, the infrastructure side is evolving to support larger volumes, faster replication, and better observability across regions.
There’s plenty left to do. Some domains still need to be extracted. Some projections need to be redesigned for scale. Some need to be designed from scratch. Our event propagation paths can get faster, and our recovery mechanisms can become more automated. The long-term goal is to reach a point where operating a distributed, event-driven system feels no more complicated to an engineer than working inside the monolith once did, but with all the resilience, clarity, and global performance benefits of the new world.
We’ve built the basic shape of the platform we want. Now we’re tuning it, scaling it, and making it something teams can rely on with full confidence as the company keeps growing.
Why This Work Matters, and Why You Might Want to Join
If you’ve spent enough years in engineering, you can tell when a team is solving real problems versus rearranging abstractions. The work we’re doing sits firmly in the first category. We’re building systems that have to hold together across continents, under real traffic (we have already reached 300k requests per second, and it is growing steadily), in environments where eventual consistency, replication delays, and partial failures aren’t theoretical edge cases - they’re everyday constraints we have to design for.
You’d be joining a group of people who care deeply about getting the fundamentals right. The problems are complex in a way that rewards good engineering instincts: modeling domains cleanly, designing robust asynchronous flows, understanding how events propagate through a large system, and building projections that remain fast and correct under load. There’s room here for engineers who enjoy thinking holistically, who appreciate clarity in domain boundaries, and who like improving the systems that everyone else will depend on for years.
You’d have influence, not in the “we have a committee for that” sense, but in the way where well-reasoned ideas actually shape how the platform evolves. If you see a gap in our tooling, you can fix it. If you find a better pattern for consumers, you can drive its adoption. If you notice a weakness in our replication or event flows, you can help redesign them. This is the kind of environment where senior engineers don’t just write code - they leave fingerprints on the architecture.
And perhaps most importantly: we’re not done. The foundations are in place, but many of the hardest challenges are still ahead. We’re scaling across new markets, pushing more traffic through the system, and tightening the guarantees we provide while keeping the developer experience simple. If you’re the kind of engineer who enjoys working on systems that matter, who wants real ownership, and who’s motivated by building the kind of platform that other teams can stand on with confidence, we’d love to talk to you.
You could make a meaningful impact here - not someday, but immediately.