Test Smarter, Not Harder: Risk-Based Data Quality Without Pipeline Paralysis
Upstream schema changes were breaking our finance pipelines daily. With monthly reporting deadlines looming, we needed to balance data quality with pipeline reliability. Here’s how we solved it without compromising either.
We obsessed over data quality. Why?
Ideally, we’d like data to be pristine. Most data practitioners accept trade-offs in data quality rather than spending copious amounts of time addressing underlying data issues. For finance reporting, the margin of error is much smaller.
Our data space concerns reporting data pertaining to shipments from Vinted’s network partners. We have oversight over carrier invoices for financial reporting. This is also corroborated with cost expectations based on shipments created and contractual terms. The data we receive from carriers comes in all shapes, sizes, and forms. Think CSV, JSONs, Parquet, Excel files. This requires us to be flexible while keeping a close eye on any schema or format changes which may inadvertently affect the accuracy and completeness of data.
Post-migration, we shifted-left in our testing approach. We implemented several tests: not null, accepted values, and expression validations close to the source. An example would be an accepted values test for cost descriptions, as they would impact whether there was a positive or negative sign applied to the invoice amount. Despite keeping only essential tests as errors (as opposed to tests that only raise warnings), our pipeline was being blocked by upstream errors.
The reality hit hard: our pipelines went from consistently high daily success to a significantly lower rate within two months. The variety of data we received changed much more frequently than we thought. Our initial attempts to stay on top of our input files were too strict.

We went back to the drawing board and asked ourselves - what is just enough? Getting bombarded by alerts and failing pipelines in the morning was eroding stakeholder confidence. Data quality that doesn’t arrive on time defeats its own purpose. We needed our pipelines to be available for consumption at the start of the working day.
Materiality and informational quality
Materiality is related to the significance of information within a company’s financial statements. If a transaction or business decision is significant enough to warrant reporting to investors or other users of the financial statements, that information is “material” to the business and cannot be omitted.
Financial accounting principles are a helpful tool for determining how to deal with data quality. We’re interested in two concepts: materiality, and the qualitative characteristics of financial information. The latter can also be understood through the Informational Quality Framework.
We revised our processes. The most crucial dates for financial reporting were at the start of the month and in the middle of the month, when financial reporting information is downloaded and reported on. At all other times of the month, the daily pipeline serves analytical purposes. In other words, localised errors with a new incoming invoice would not be significant enough to influence someone’s decision-making process. Therefore, we could afford to be less strict on localised errors.
Data quality can be viewed through the lens of the Informational Quality Framework:

In our context, this would mean:
- Accuracy: If the mart says the shipment was invoiced for 5€, was it the same at source?
- Completeness: Are all 100 shipments invoiced reflected in data products?
- Timeliness: Can I see the updated data by the start of the work day?
The framework also highlights other qualities such as consistency, accessibility, and interpretability. The reference to the paper is included below.
With these quality dimensions defined, we still faced a practical challenge: how do we translate abstract concepts like “materiality” into concrete testing decisions? We needed a systematic way to determine which data quality issues truly mattered for business decisions versus those that were just “nice to have” perfect. This led us to develop a framework that combined business impact assessment with frequency patterns.
The risk-based approach
Setting guidance on materiality in view of accuracy and completeness grounded us in assessing the potential impact to the team. After several months of observing schema evolution with an overly strict testing regime, we had a sense of how frequent exceptions occurred.
This allowed us to conceptualise the risk-based testing framework, based on the issues’ impact and frequency. The framework helped us reduce daily pipeline failures while maintaining critical data quality checks.

We took a more cautious approach. High impact risks should be avoided at all costs. For low impact but high frequency exceptions, we reduce the risk by monitoring them more closely. Alerts are triggered when there are exceptions, and there are tests that run daily. In cases where the exception doesn’t happen often and is unlikely to have high impact, we accept the risk. We monitor them in weekly reviews, without the need to trigger an alert every day.
These are some examples:

We only kept high impact tests in the main run. dbt build by default runs all tests, whereas we opted to exclude a substantial number of tests which look out for low impact silent failures. This helped us make the main run leaner while preserving checks.

Translating this to code
We tag tests and use exclusion flags to build models and run tests.
On a test-level, in the model’s configuration:
data_tests:
# Missing amounts break financial reconciliation
- not_null:
column_name: invoice_amount_eur
config:
tags: highimpact_highfrequency
# Duplicate tracking IDs corrupt cost allocation
- unique:
column_name: shipment_tracking_id
config:
tags: highimpact_lowfrequency
# New cost types appear occasionally, can be mapped later
- accepted_values:
column_name: cost_description
values: [delivery, return, surcharge, fuel_surcharge]
config:
tags: lowimpact_highfrequency
# Occasional date parsing errors, rarely material
- expression:
expression: "invoice_date >= '2020-01-01'"
config:
tags: lowimpact_lowfrequency
In dbt_project.yml:
models:
vgo_finance:
+meta:
excluded_tests:
# This way, only high impact tests run
- tag:lowimpact_highfrequency
- tag:lowimpact_lowfrequency
sources:
vgo_finance:
+meta:
excluded_tests:
# This way, only high impact tests run
- tag:lowimpact_highfrequency
- tag:lowimpact_lowfrequency
Our dbt project is split up into different tasks in Airflow. We have internal orchestration that reads the +meta.excluded_tests configuration and turns it into --exclude flags when calling the dbt CLI. See this article on our Airflow set-up: Orchestrating Success.
Stock dbt does not interpret meta in this way, so if you do not have similar tooling you should pass --exclude directly to dbt test / dbt build, as in:
# Main pipeline run - only critical tests
dbt build --exclude tag:lowimpact_highfrequency tag:lowimpact_lowfrequency
# Daily monitoring run - low-impact high-frequency tests for alerting
dbt test --select tag:lowimpact_highfrequency
Managing a process change

This was an exercise of change management. In order to obtain a mandate to prioritise these tasks, we needed to first have a consensus that there was a problem. Thereafter, while gathering requirements, we wrote an RFC and took action.
The key is in recognising that when data quality issues arise, they’re very much related to process deficiencies. People who interact with the process need to be engaged as an essential part to ensuring the process succeeds.
Designing for continuity: first principles and inversion as a mental model
First principles thinking is a problem-solving method that breaks complex issues down into their most fundamental, foundational truths, rather than reasoning by analogy or convention.
Inversion thinking is a problem-solving technique that flips challenges upside down by focusing on how to avoid failure rather than solely on how to achieve success.
On data quality issues, we zoomed in on testing at source to ensure completeness. We focused on key pieces of information like the invoice amount, the date, and the cost description. We tried to imagine how, and asked, our stakeholders would check for these issues. What would they want to know about the information, and what could help them resolve it as quickly as possible?
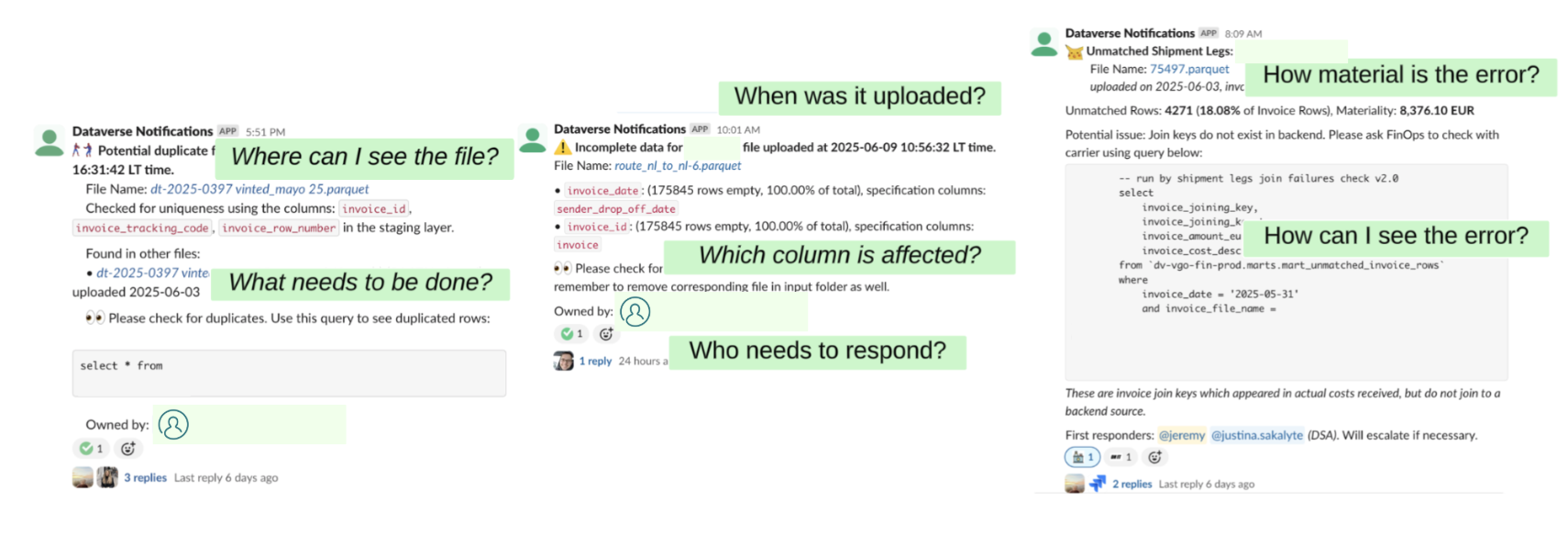
This is an iterative journey. Expectations are similarly built with time. When we started with alerting on source issues, the situation we wanted to avoid was not catching them at all. This resulted in an alert, but it wasn’t obvious what someone needed to do with it until they looked at a Google Sheet. This expectation evolved to us thinking - any solution cannot be unactionable; in other words, looking at the alert should allow someone to immediately know what to do with it.
The key insight: actionable alerts build trust, while noisy alerts erode it. We learned this the hard way when our Slack channel went from essential updates to a source of alert fatigue.
We will keep revising, and learning. For now, we have something that balances alerts (preventing fatigue) while ensuring quality and building trust.
Appendix
We’ve also shared our work at the Forward Data Conference. Do check it out!
Some prior research referenced is:
- Prochaska, J. O., Norcross, J. C., & DiClemente, C. C. (2013). Applying the stages of change. Psychotherapy in Australia, 19(2), 10-15.
- Eppler, M. J., & Wittig, D. (2000). Conceptualizing Information Quality: A Review of Information Quality Frameworks from the Last Ten Years. IQ, 20(0), 0.
- IFRS Foundation (2018). Definition of Material, Amendments to IAS 1 and IAS 8.