Scalable and non-blocking event ingestion pipeline? Here's how
Every day Vinted gets a few billion events from our customers via mobile phones or web clients. Every time a user clicks somewhere, views an item, views another user’s profile, buys something, leaves feedback, etc., a JSON representation of that action is sent. And it’s a long time (at the time of writing, about an hour) before that same JSON from plain text arrives in our hard drives, compressed and available for our analysts. Only then can we start querying and drawing more insights from this valuable information.
First step: the client
If you use the Vinted app, then your actions buffer inside your phone. We don’t just send events over the wire the second the client does anything. It’s better to send mobile-phone events in a batch, rather than one-by-one – this prevents too many TCP connections opening at the same time and also helps save phone battery. A new batch of events is sent either when there are enough events to meet the threshold or when enough time has passed – whichever comes first.
The events are on their way – now what?
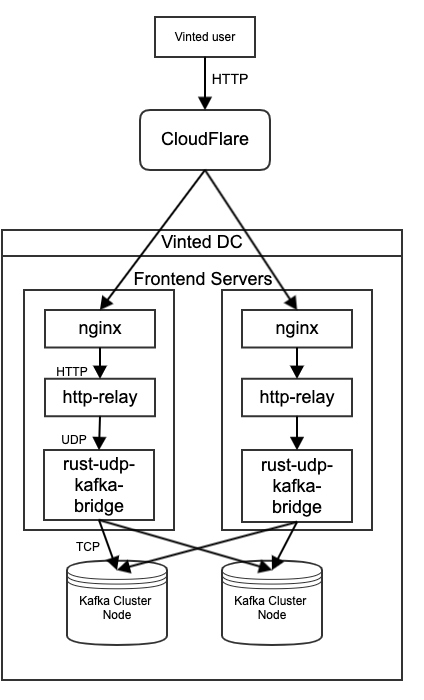
Now events are travelling to our front-end Nginx servers. There’s nothing Nginx can’t handle, so there won’t be any surprises there. Nginx now load-balances with our service called HTTP Relay. HTTP Relay is a Node.js service that creates many Node.js workers to do the actual processing. Basically, one Node.js service is a front that forwards traffic to its workers.
So what does this service do to the event after receiving it from Nginx? It splits all events from the HTTP request (because we send them in batches). Here’s where we can fix corrupted app events in flight, in real time. For web events, it’s simple to catch something, make tracked changes to the front end or back end, and release it instantly.
Not so with mobile apps. The mobile app release cycle takes about two weeks. Occasionally, we release a new version of the app that sends the wrong event format (it may contain typos or other small errors). This can result in the bad event being continually sent for two weeks, until the next release.
We’re all human, we make mistakes, so this Node.js service is a good place to patch those mistakes. We can check the event version/app version, check if this is the bad event that’s being sent, and then fix it on the fly. This is very convenient in a dynamically typed language like JavaScript.
Note: To avoid fixing events in-flight, we started generating code from our Schema Registry in Kotlin (for Android) and Swift (for iOS) – so there’s no way someone could make a mistake by sending an event. At this point in time, we still need to do the same for the web front-end.
Once events are split and, if necessary, fixed, they are passed down to the localhost UDP port one-by-one using the same server that’s received by our UDP to Kafka bridge.
UDP
Why UDP? Imagine we’re on the back end, the customer has made the payment, they’re about to be directed to the “thank you for your purchase” page, we try to log the purchase event in the back end, and all of a sudden – 500 Error. Or, even worse, a timeout. The moment when we send the event – which is supposed to help improve the user’s experience – can actually ruin the user experience, if it doesn’t work. Of course, you could say, “use async HTTP and ignore the result”. However, the TCP connection is still open, there’s a non-stop firehose of events, and any hang-up on the receiving HTTP end will exhaust any TCP connection pool we can fit on one machine. Sure, the connection to the previous Nginx is HTTP, and Nginx forwards HTTP – but once we get it from Nginx, we only do everything in the process itself. We don’t connect to databases, we don’t connect to Kafka, we don’t write to our backend storage (currently HDFS) – we just need to pass the events we receive on to the UDP to Kafka bridge and we’re done. So, we never block.
Do we lose events when moving them in UDP to localhost? Sure – from time to time, the Linux UDP buffer is full and not able to cope with all the events (especially if the server that the Rust bridge is running on has other neighbours that use up a lot of CPU). We’re not too worried about this at the moment because we’re only losing a negligible number of events this way.
We also had some issues where the UDP service wasn’t running at all. We lost events for a few hours, but nobody using Vinted had a chance to notice it. I and my buddy Lech were sweating at our computers knowing what was happening and trying to fix it – but thankfully it didn’t have a noticeable impact for anyone using the product!
UDP to Kafka bridge
This service does pretty much what it says: it gets the events from the UDP port and puts them into Kafka (all in one topic). This service is written in Rust for maximum performance and runs in parallel on the same servers that the Node.js HTTP Relay service runs on, so that we don’t need to send UDP over the network but rather over OS, which makes it much more reliable.
The Vinted event ingestion pipeline was built in 2014, when Rust hadn’t even reached 1.0. We had an equivalent service written in Clojure. However, there came a day when the JVM instance running on 1GB RAM couldn’t cope and would begin restarting. We tried giving it 2GB – same problem. 4GB – still OOM. 16GB – no deal. Fun fact: OOM errors like that are why we called our team Out of Memory.
Sure, I guess we could’ve spent a lot of time trying to figure out all the ins and outs of the JVM and we might’ve gotten it to work. However, this service was so simple that we decided to rewrite it in Rust. We’d already had a great experience with Rust when we patched StatsD to use it internally for all the infrastructure metrics at Vinted. We’d just forgotten about it after putting it in production (and after fixing a few deterministic issues), so why not rewrite this service with Rust?
It took one day. And we’ve forgotten that it’s running ever since. We didn’t need to check Rust runtime flags, we only had to compile the Rust binary with --release flag and it just ran.
We used the amazing Tokio library to have overheadless IO for our service. We learned at the time that using a standard library to listen on the UDP port for StatsD wasn’t as efficient and we were losing datagrams. But after switching to Tokio for our IO we’ve been very pleased with the performance.
We have two threads in this service. One thread just receives UDP messages and puts them into a memory message queue (std::sync::mpsc::sync_channel) and then the other thread receives the UDP message. Our memory queue has a configurable size of 10 million messages at the moment, so even if Kafka is down we can store up this many messages without losing a single one (assuming the server doesn’t restart during that time, which is a rare case) and then still dump all of those messages to Kafka when it turns back on. Once the queue is full it will block the UDP thread, which causes us to lose events at the Linux UDP buffer level, as we can no longer accept them.
After receiving a message from the memory queue, we put it into Kafka using librdkafka with mostly default params, except that we use Snappy for compression to lower traffic to Kafka and acks=1.
We were very pleased with the low memory usage of this service. It starts out very small at only 10MB and during peaks its memory queue expands process memory to ~240MB and stays there.
Now we’re in Kafka cluster
The event is now in Kafka. All events go into one topic – we simply increase its partitions as the topic grows. This topic has a 7-day retention, and its consumption is usually at the front. Even if we have an incident at this point or the consumer starts lagging, we still have 7 days to fix it before Kafka drops the segment and we lose these events for good. The producers of that topic are Rust-UDP-Kafka-bridge instances and the consumers of that topic are… well, you’ll find out in our next post!
Here’s an illustration of this flow:
Conclusions
Just get it in Kafka and chill
Kafka is the first real persistence layer that we have. Once we get events in Kafka we can relax. We know events are persisted and we know Kafka nodes can go down – but we still can retrieve them. However, we do need to make sure that the path from user HTTP request to Kafka is as short and as smooth it can be.
UDP is a useful non-blocking black hole
There will be a point where something bad happens and events will have to disappear. Unfortunately, under current circumstances, we cannot choose whether they will disappear. But you can choose where they will disappear to. And UDP is a very useful place where they can disappear to without disrupting business logic flow. Unlike TCP, where you need to block and sling multiple packets back and forth just to open a connection, in UDP you just send a datagram. It may reach the end or it may not, but you don’t need to worry about it – plus, it works well and is reliable during a smooth operation.
Rust is awesome
Even if you don’t know Rust, if you ever need to make sure you get the most of your hardware, just try learning it. I used to be C++ guy, and to master C++ you need to invest an astronomical amount of time. Sure, you won’t master Rust in few days either, but you can still put up zero overhead code without a headache even while not knowing the best practices. When I first saw Rust talk and what it does, being an entrenched native C++ guy, I thought it was a godsend. I would never be able to write C/C++ without having to deal with weird, cryptic segfaults. With Rust, you just don’t worry about that at all. You write code and if it compiles you will not have a segfault. How awesome is that? Zero overhead code for everyone, regardless of their skill level.