Data center network at Vinted
During the last year, Vinted SRE team reimplemented the whole data center network starting with new equipment, finishing with the topology and architecture change. The project had its ups and downs: things that seemed complex at the start became trivial with a change in point of view, and the seemingly trivial tasks revealed unanticipated, hidden complexities. We hope it is an interesting story to read.
TL,DR: We migrated from several large plain subnets spanning three physical locations to Clos topology with eBGP for routing and AS per rack with anycast service addresses and EVPN for multi tenancy. We deployed with Ansible and conducted integration testing with Kitchen-InSpec.
And here comes the longer version.
Motivation
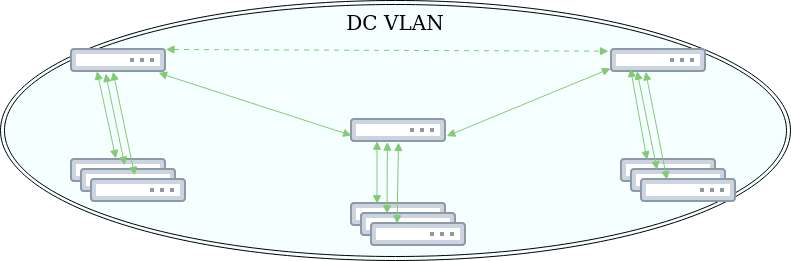
When Vinted first started building its infrastructure, there were tens of servers and nobody really cared too much about the data center network. It just worked. When the infrastructure grew to hundreds of servers and tens of gigabits of traffic, it became obvious that the current network architecture did not scale well and could cause serious service outages because of its large blast radius.
Planning
When we chose our new network architecture, we wanted to:
- Have an architecture that we could scale tens of times, measured by connected network devices and traffic.
- Have high availability and be able to lose any hardware unit without downtime.
- Avoid vendor lock-in as much as possible.
- Be able to manage our network equipment as similar to servers as possible. By that we mean:
- to have all configuration deployable from our git repository;
- to have integration tests on development environments;
- to be able to use similar monitoring and alerting tools as on our servers.
After some consideration, we decided to give the Cumulus Networks solution a try, as it fit quite well into our requirements. Their software can run on many switches from different manufacturers. The operating system on the switch is debianish Linux distribution, comfortable for us to manage and for our tools to run on. The main routing daemon is an open source FRR and switch silicon is presented transparently to applications through Linux kernel as a standard Linux device and kernel data structures.
We agreed on principal network topology, ordered a bunch of Cumulus switches and started to plan for migration.
The first consideration was which configuration would we migrate to our existing servers. Seeing as most of them were in one large subnet, the straightforward way was to change our current network equipment to a new one configuring the same large L2 subnet, but to configure MLAGs between Top Of the Rack (TOR) and core switches. It would grant us more bandwidth, a bit of high availability, but would not meet all the requirements listed above.
Our second scenario was to deploy the EVPN overlay on the Clos underlay network. This scenario seemed to have many benefits, as it allowed us to have multiple active paths on the L2 network domain without causing network loops or the need for STP. But it still seemed to have some scalability issues, since every server address needed to be announced to every switch. Also, a misconfiguration of a single server could cause significant problems as in the plain L2 segment.
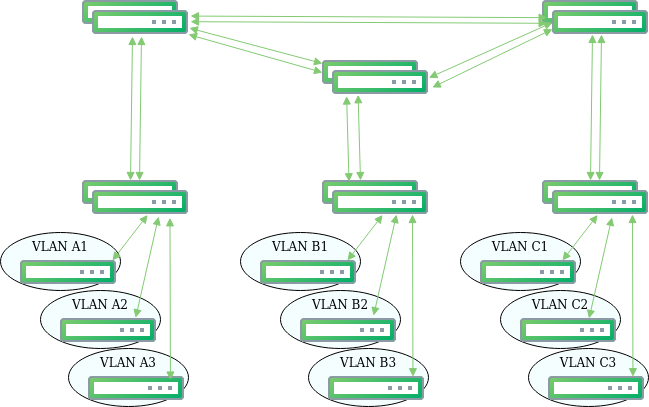
Finally, we decided to listen to the “route early” advice from Cumulus and agreed to limit subnets of our main infrastructure to one rack. Our project fit well into classical Clos topology: every server rack has its own subnet, and the TOR switch (in Clos topology it’s called a leaf) acts as its gateway. All leafs have routed point to point subnets with aggregating switches, also known as spines. With Cumulus, such configurations are even simpler, because of BGP unnumbered feature there is no need to configure static IP point-to-point connections between leafs and spines.
Network migration
Here arose our first technical challenge: In order to migrate hundreds of servers from one large subnet to many smaller ones, we needed to change the IP addresses of all hosts and to physically reconnect servers to the new network. With no downtime. We wanted to have a procedure where it would be simple to undo any migration action and where we could migrate server by server without shutting down any of our clusters. Also, we wanted to avoid introducing new single points of failure to our network.
We decided to use a little trick: to deploy a new network in parallel with the old one and to create connections between them in every rack. As our new network was a pure routed solution, we could do it without causing a network loop. Also on every leaf switch we have configured a secondary IP address from the old network, so all leaf switches became routing gateways to it. We added additional routes to the new network on our servers through the same secondary IP addresses. Now we could do physical server reconnection and IP reconfiguration in two independent steps. The traffic between new network addresses should go through routed paths in the new network, traffic between the old server addresses through the old plain subnet and between them through our new secondary IPs. Right? Wrong.
Let’s start with ICMP redirects. And CentOS 6 boxes, which learned and cached “more optimal” routes to hundreds of hosts from other subnets that are reachable directly, bypassing gateways. And switches, which filled their ARP tables with broadcasted messages from other subnets, as we have connected them to the same broadcast domain. And ARP tables, which had precedence before routing (only later we found out that this precedence is configurable).
And that’s where a proper monitoring solution came in, as it helped us understand these nuances by observing low traffic on leaf - spine ports before we tried to disconnect our networks. We created several one-liners for chef knife and Ansible to flush server route cache and to delete some particular entries from the ARP tables. It enabled us to disconnect racks from the old network without disturbance to our systems.
In this part of the project we ignored some fundamental good practices (temporarily) and introduced significant additional complexity. We did add a lot of monitoring though. In the first stages of the migration process we took our time to understand how traffic flows in our environment exactly. With this visibility, we managed to move our clusters server by server to the new network topology.
Internal network (underlay)
What did we achieve with this change? As mentioned above, we used two layer Clos topology. Every rack of servers has it’s switch (leaf switch in Clos nomenclature), all servers in the same rack belong to the same subnet and the first hop gateway is configured on the switch.
In the core of every data center there are ‘spine’ switches, every one of them providing an independent path between leafs. Every leaf is connected to all of the spines, but spines do not have direct connectivity.
Links between all switches are routed L3 interfaces. BGP protocol is used for route management. Every leaf has it’s unique AS number and announces all the subnets connected to it to the network. The spines in the same DC share the same AS number to prevent non-optimal network paths.
The Equal Cost Multi Path (ECMP) option is configured on all switches, so between every two racks there are as many paths as there are spines in the data center. The path for traffic is chosen by hashing source and destination IP addresses and ports.
In a data center setup BGP has much more aggressive timers, than usually configured on the internet. If some spine fails, it is removed from active paths in several seconds and the affected traffic takes an alternative path. What if the leaf fails? Then we lose the rack. It is by design, none of the racks in our infrastructure should have a critical count of servers from any cluster to bring it down on failure. The high availability of network equipment on the rack level can be achieved by dual attaching servers to two switches, but then we need to double the number of leafs and to use some multi switch link aggregation protocol, usually with primary - secondary device pattern. In the end it almost doubles the cost of the network equipment and introduces additional complexity. And a rack still can go down in case of some nasty PDU failure, unanticipated cooling issue, etc. etc.
Talking about primary - secondary device pattern, we avoid using it on network equipment including MLAG, VRRP and similar protocols. The goal is to have every network component behave independently of other components and to announce its services by BGP.
On the edge of every our data center we have several exit switches. From the point of view of topology they are the same as leafs, but provide connectivity to external network resources - our other locations and internet providers.
The leaf switches have one more functionality - they accept BGP sessions from the servers on the same rack. It allows us to have anycast services in our internal network, for example as there is a public Google DNS service available on 8.8.8.8 IP advertised from multiple locations on the internet, we can have several internal DNS servers in every data center, with some IP address configured on loopback (f.e. 10.10.10.10) and advertising a 10.10.10.10/32 route to their leafs. As the traffic is routed to the shortest AS path, the service on the same rack is automatically preferred, if it is not available the traffic would be equally distributed between instances on the same DC and in case there are no instances on the same DC - forwarded to other data centers.
External network (overlay)
In Vinted we already used anycast IPs, advertised from several ISPs for our front servers. It proved to be a good solution for load balancing and high availability, but we had one fundamental design problem: there is no such thing as a ECMP between several providers on the internet, so if we advertise anycast IP from several ISPs, usually one ISP with shortest AS path or lowest AS number wins all the traffic from similar locations. If these locations are dominant (f.e. Cloudflare node), the traffic is heavily unbalanced. Back to the drawing board.
The simplest way to balance traffic seemed to be on the DNS level. But DNS TTL is not respected on the internet sometimes, so DNS cache can take a long time to expire and BGP convergence is much faster. DNS depends on health checks as well and it requires to completely change how we manage DNS records.
At this point we realised that incoming traffic is negligible compared to outgoing, that is understandable, because a small http request asks for a large document or image. So the actual problem was not to balance all the traffic, but to balance the outgoing traffic. And it can be done with BGP easily :)
The idea was to create virtual networks on top of our infrastructure, where front servers would belong to the subnet of DC where they reside, but all exit switches would have interfaces in all the subnets. Front servers have BGP sessions with every exit switch, so when traffic reaches our infrastructure from the internet, independently from which ISP it comes, it is distributed evenly between all active front servers. We had to create a topology, where all front servers would be on the same subnet as exits because if we would redistribute routes with intermediate BGP host, the traffic would not be evenly distributed.
We see recent enhancements in routing software where weight can be assigned to ECMP balancing, but they were not available half a year ago when we created this topology and we did not research this possibility yet.
For the virtual network we use two main technologies: VRF for separate routing table and BGP instances and EVPN for the L2 network virtualization.
EVPN uses BGP under the hood to distribute information, such as mac and IP address locations in the network and VxLAN encapsulation for traffic forwarding.
Network automatization and integration testing and monitoring
We wanted to continuously deploy the configuration repository from the very start. We use chef to manage our server fleet, but it seemed a bit of an overkill to have a chef client running on every network node, that’s why we decided to stick with Ansible because of its agentless architecture.
We have inventory files where our topology is described on the higher abstraction levels (like what AS number and subnet is present on what rack or to which port the front server with external network is connected) in our Ansible repository. This inventory is converted into configuration files by Ansible roles with templates on deployment.
The interesting thing about Cumulus network devices is that because it runs mostly standard Linux and ports on the switch hardware are presented as virtual devices to Linux kernel, it is very easy to emulate a production network topology on virtual machines. Even the standard tooling to generate vagrant files from topology described in the dot format is provided.
There are two inventories in our Ansible environment - virtual for development and production for the real network devices. By the way, every configuration deployment is executed on a virtual environment by default (if not stated explicitly to deploy to production).
When we started the project testing was mostly manual - you wrote the code, deployed it to dev environment, did some sanity checks manually (like pinged some hosts and looked into the routing tables where changes were being made) and if everything seemed fine you created a pull request, got some approvals and deployed it to production. When the codebase grew we noticed some potentially disruptive configuration changes sliped through our manual testing and PR process and were cought just before production deployment. At that time we took a detour from our main migration project to cover our functionality with automatic integration tests.
We chose Kitchen-InSpec as our testing framework - mostly because we use it for our infrastructure and everyone in our team is comfortable with it. We created custom InSpec resources to be able to ping an address from a particular virtual machine and VRF, as well as to verify a routing table, other running configuration and state on any switch in the development environment.
We have a full CI pipeline now - on every PR to the network repository a Jenkins job is triggered. It creates a vagrant file, launches virtual topology on build server and runs full InSpec tests. The merge is allowed only if all tests pass. Deployment is still done manually by triggering Ansible playbooks, because the project is in a very active state and many big changes are still in progress. Final configuration is often once more reviewed for possible differences between virtual and production environment. The end goal is to do a continuous deployments, but it is still an ongoing journey as we need better tooling to be confident, that we can do network deployments in a staged fashion (where our services could tolerate any failure on one stage and such failure would be detected and would stop the deployment).
We use Prometheus to monitor our network. Most of the data is gathered by a standard node exporter. We plan to create some additional tooling to monitor network specific parameters in the future.
Conclusion
We have undertaken the project to reimplement our data center networking changing all the components: hardware, topology and the protocol stack. Although the migration process was not a straightforward one, now, when it is finished, we are much more confident in our network infrastructure. We can deploy it faster and scale it far beyond the limits which were imposed by the architecture we had previously.
Further reading
Most of the network technologies used in this project are well covered in Definitive Guide: Cloud Native Data Center Networking by Dinesh G. Dutt. This book is a great read for anyone who wants to dive deeper in current trends of data center networking, although the Cumulus architecture and open routing suites get most of the attention, a fair effort is made to present different approaches used by other big vendors.
We did not open source our network automation code yet. The main reason - it is still coupled with our infrastructure and has a lot of complexity left from the migration process, but we hope to have more generic modules later we could share on github.