Vinted Search Scaling Chapter 1: Indexing
Data ingestion into Elasticsearch at scale is hard. In this post, I’m going to share a success story of leveraging the Kafka Connect Elasticsearch Sink Connector to support the ever-increasing usage of the Vinted platform and to help our search engineers to ship features quickly all while having an operational and reliable system.
Prehistory
Several times postponed and endless times patched with magic workarounds like future jobs, delta jobs, deferred deduplication, delta indexing, etc. - it is time to rethink this solution.
— Ernestas Poškus, Search SRE Team Lead
Scope of the Post
The job of the indexing pipeline is to bridge the gap between the primary datastore that is MySQL and the search indices backed by Elasticsearch. For the building blocks of the indexing pipeline, we picked Apache Kafka and Kafka Connect.
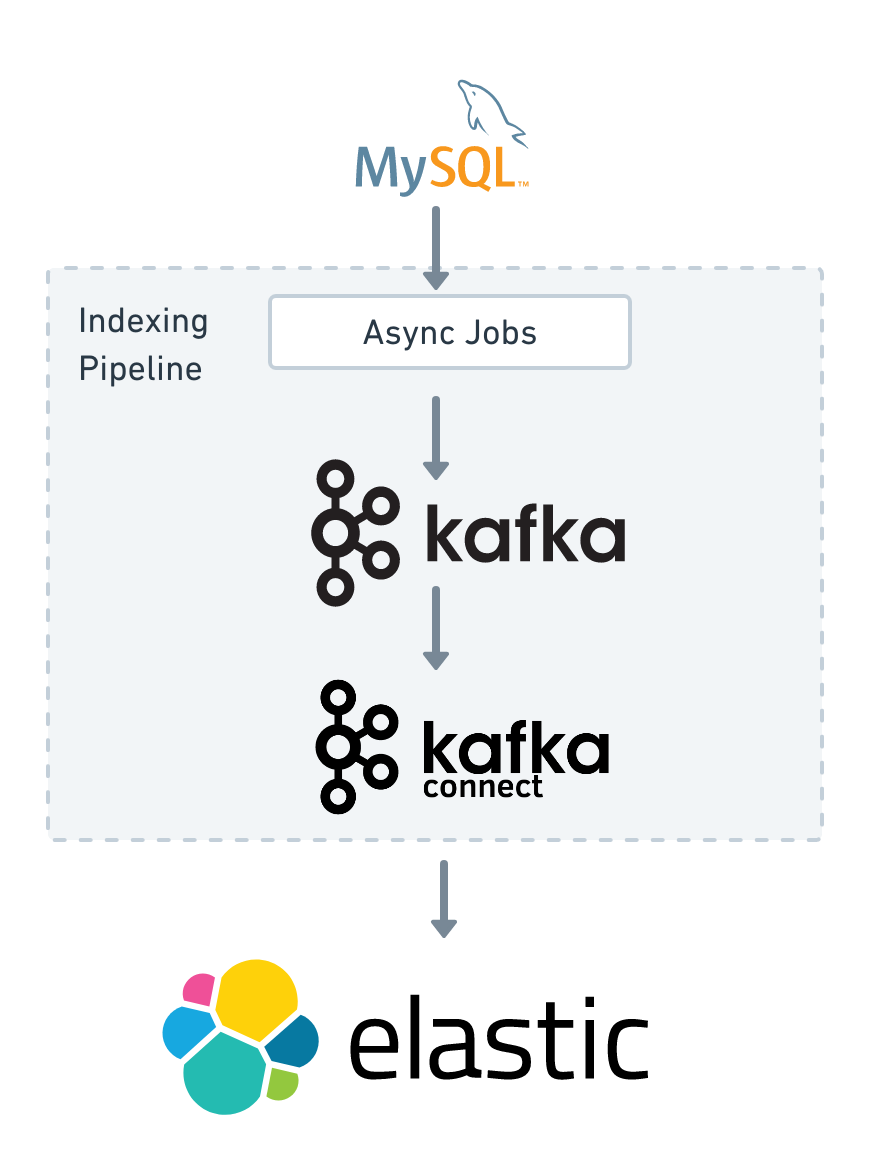
The term Async Jobs in the chart above refers to a collection of Ruby scripts that periodically check the database for updates that happened during the last several minutes. Updates are then sent to the appropriate Kafka topics.
We have a separate Kafka cluster for handling the search use cases. Kafka serves as a high-performance, durable, and fault-tolerant buffer.
Kafka Connect is a scalable and reliable tool for streaming data between Apache Kafka and other systems. It allows to quickly define connectors that move data into and out of Kafka. Luckily for us, there is an open-source connector that sends data from Kafka topics to Elasticsearch indices.
From now on, this post will focus on the details of our Kafka Connect deployment: how we use the system, and its properties. Also, we’ll share the battle stories and lessons we learned while implementing the solution.
Requirements of the Data Indexing Pipeline
We started the project with a list of requirements. The following list captures the most important ones:
- Capturing the ordered set of data indexing operations (to act as a source-of-truth);
- Scalability and high-availability;
- Ensuring the delivery and consistency of the data;
- Indexing data to multiple Elasticsearch clusters that are of different versions;
- A programmable interface that allows to control the indexing pipeline;
- Support of manual throttling and pausing of the indexing;
- Monitoring and alerting;
- Handling indexing errors and data inconsistencies;
We researched several available open-source tools for the indexing pipeline. Also, we considered the possibility of implementing such a system ourselves from scratch. After evaluating, Kafka Connect seemed to be the way to go.
Capturing the ordered set of updates to the Vinted Catalogue
We expect to store the data indexing requests for as long as needed. To achieve that we set retention.ms to -1 for all the relevant topics, i.e. we instructed Kafka not to delete old records. But what about storage requirements of the Kafka cluster if we don’t delete anything? We leverage Kafka’s log compaction1 feature. Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. Or in other words - Kafka will delete old records with the same key in the background. This strategy allows to “compact” all the updates of a catalog item into one update request.
Kafka topics contain records where the record key is an ID of the Elasticsearch document, and the record body is the _source of the Elasticsearch document. The body is stored as a JSON string. Note that the record body is always a full document, meaning that we don’t support partial updates to the Elasticsearch documents. There is a special case when the Kafka record body is null. Such messages are called tombstone messages. Tombstone messages are used to delete documents from the Elasticsearch indices.
Scalability and High-availability
Kafka Connect is scalable. Kafka Connect has a concept of a worker, which is a JVM process that is connected to the Kafka cluster and a Kafka Connect cluster can have many workers, and each connector is backed-by a Kafka consumer group which can have multiple consumers instances. These consumer instances in Kafka Connect are called tasks, and tasks are spread across the workers in the Kafka Connect cluster. However, the concurrency is limited by the partition count of source topics: it is not recommended to have more tasks per connector than target topics have partitions.
On top of that, the Elasticsearch connector supports multiple in-flight requests to Elasticsearch to increase concurrency. The amount of data sent can be configured with the batch.size parameter. How often the data is sent can be configured with the linger.ms parameter.
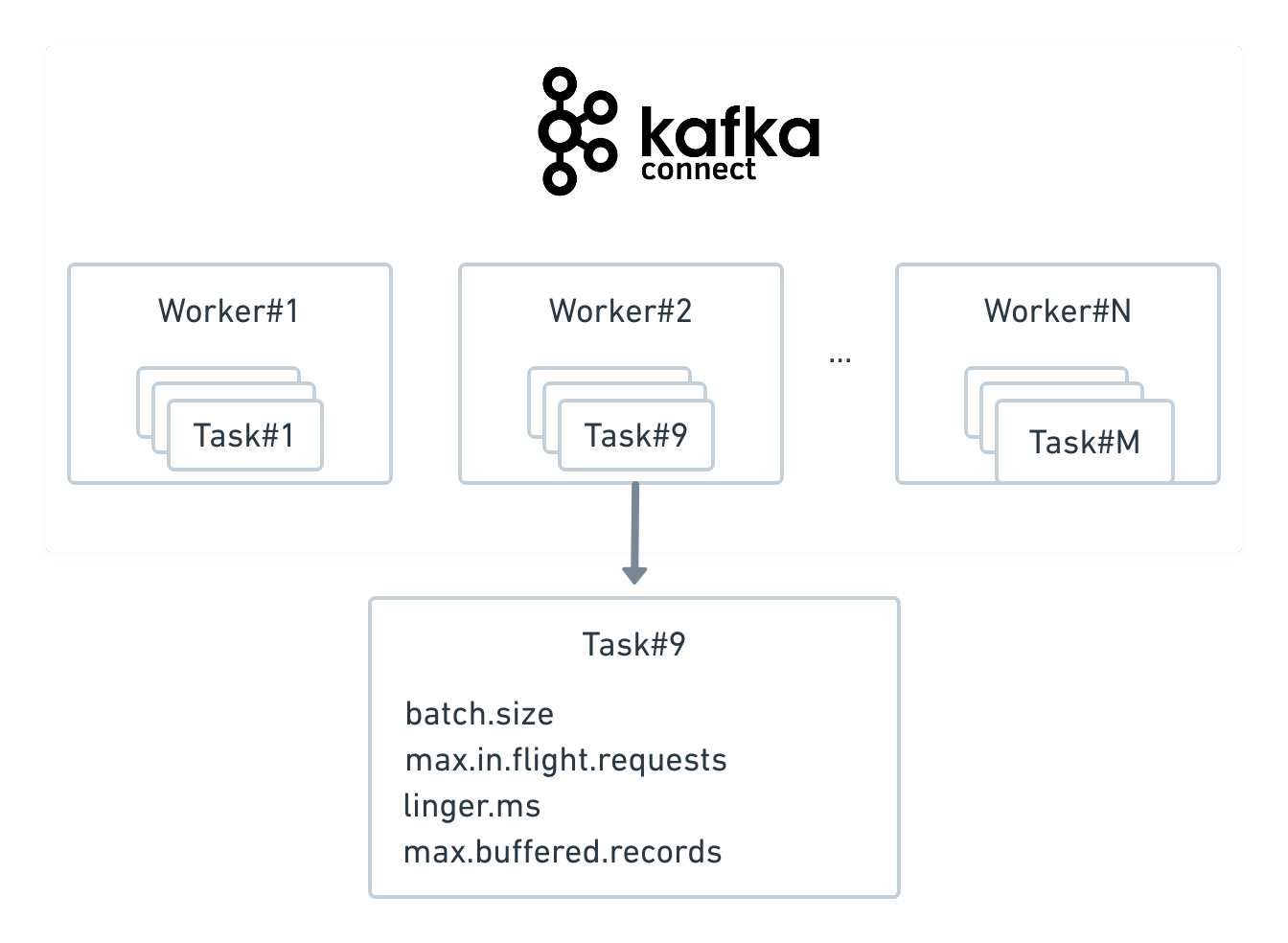
It is worth mentioning that one connector can index data to one Elasticsearch cluster. To support multiple Elasticsearch clusters you just need to create multiple connectors.
High availability is ensured by deploying Kafka Connect workers over multiple servers, so that each task of the connector fails independently. An advantage of this is that failed tasks can be restarted one-by-one.
Elasticsearch Client Node Bug
We used Elasticsearch client nodes to perform the load balancing during indexing of the data into Elasticsearch clusters. However, occasionally, we had to kill and restart client nodes because they failed with an error:
{
"error": {
"root_cause": [
{
"type": "circuit_breaking_exception",
"reason": "[parent] Data too large, data for [<http_request>] would be [33132540088/30.8gb], which is larger than the limit of [31653573427/29.4gb], real usage: [33132540088/30.8gb], new bytes reserved: [0/0b], usages [request=0/0b, fielddata=0/0b, in_flight_requests=739583758/705.3mb, accounting=0/0b]",
"bytes_wanted": 33132540088,
"bytes_limit": 31653573427,
"durability": "TRANSIENT"
}
],
"type": "circuit_breaking_exception",
"reason": "[parent] Data too large, data for [<http_request>] would be [33132540088/30.8gb], which is larger than the limit of [31653573427/29.4gb], real usage: [33132540088/30.8gb], new bytes reserved: [0/0b], usages [request=0/0b, fielddata=0/0b, in_flight_requests=739583758/705.3mb, accounting=0/0b]",
"bytes_wanted": 33132540088,
"bytes_limit": 31653573427,
"durability": "TRANSIENT"
},
"status": 429
}
The error above looks as though we simply sent too much data to Elasticsearch at once. Normally, this can be easily mitigated, for example by reducing the batch.size parameter in the connector or decreasing indexing concurrency. However, the error still didn’t disappear. After some investigation we discovered that the problem was being caused by a bug in Elasticsearch client nodes.
Our workaround was to send indexing requests directly to the data nodes.
Handling Data Consistency
To ensure that Elasticsearch contains correct data we leveraged the Elasticsearch’s optimistic concurrency control machanism combined with at-least-once delivery guarantees of Kafka Connect and the fact that Kafka ensures message ordering per topic partition when records have an ID. The trick is to use Kafka record offset as a _version of the Elasticsearch document and set the version_type parameter to external for indexing operations. Handling of the details falls on Kafka Connect and Elasticsearch.
Elasticsearch Connector Bug
While testing the Kafka Connect we discovered that it is still possible to end up having inconsistent data in Elasticsearch. The problem was that the connector did not use the record offset as a _version for delete operations. We registered the bug in the Elasticsearch sink connector repository.
The bug affected setups where Kafka Records have non-null keys, send multiple indexing requests with data from the same partition in parallel, where they represent either index or delete operation. In this case, Elasticsearch can end up having either data that it should not have (e.g. item is sold but is still discoverable), or not having the data that it should have (e.g. item is not in the catalogue when it should be).
We patched the connector and contributed the fix back to upstream. As of this writing, we are maintaining and deploying the fork of the connector ourselves, while we wait for the Elasticsearch connector developers to accept our pull request and release a new version with the fix.
UPDATE: the issue seems to be fixed but is not released. However, it was done not by accepting out pull request but using a different library to handle the Elasticsearch indexing.
Corner Case Adventure
On a regular day, the described setup is worry-free from the data consistency point-of-view. But what would happen when an engineer increases the number of partitions of Kafka topics for the sake of better throughput in the Kafka cluster? Data inconsistencies happen. The reason behind it is that the record routing into partition changes and (most likely) records ends up being recorded in a different partition and even more importantly: with smaller offset. From Elasticsearch perspective the new records are “older” then the actually older records, i.e. updates to the index are not applied.
Unfortunately, the described situation happened in our setup. Fixing the issue required to reingest all the data into the new topics (because current topics are “corrupted”) and to reindex the data into Elasticsearch. Instead of going this path, we used this “opportunity” to upgrade the Kafka cluster to the newer version. The benefit of this approach was that the topic names could remain unchanged. Which required no changes in our indexing management code. On the flip side, we had to maintain two Kafka clusters for the transition period.
Handling of failures
Out of various options to handle errors with the Kafka Connect, we opted to continue processing despite the fact that some error occured while manually investigating the errors asynchronously in the background to minimize the impact to the indexing pipeline.
In case of an error, the idea is to send the faulty Kafka record to a separate Dead Letter Queue (DLQ) topic with all the details in the Kafka message record2 header, log the problem, and when more than a couple of errors happens during a couple of minutes, send an error message to the Slack. It is said that a picture is worth a thousand words, so let’s visualize that last longish sentence with a neat diagram:
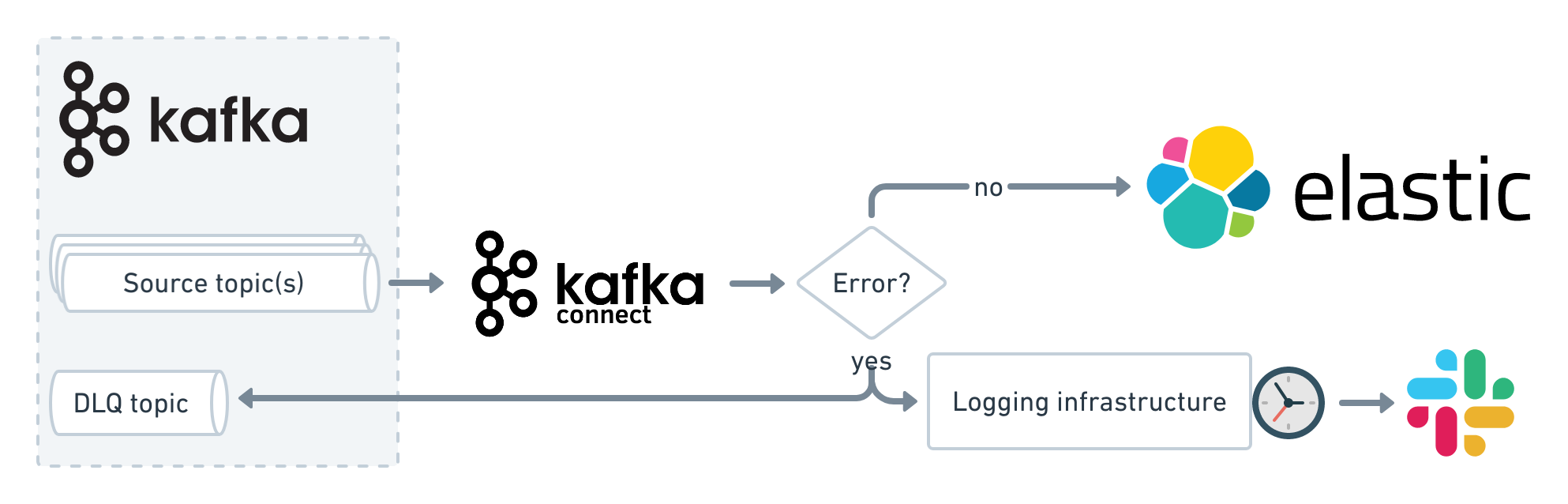
Which errors are handled by the process above? Two cases: (1) when the data is in the wrong format (e.g. the record body is not a valid JSON) and (2) when single message transforms (SMT) are failing. A notable exception is that Kafka Connect doesn’t handle errors that happen when sending requests to the Elasticsearch bulk API, i.e. if Elasticsearch rejects request then errors are not handled as previously described, just logged. Kafka Connect logging is set up to send logs to common logging infrastructure that is described in excellent detail in the post “One Year of Log Management at Vinted”.
A snippet of relevant settings from the connector configuration3:
"errors.tolerance": "all",
"errors.log.enable": "true",
"errors.log.include.messages": "true",
"errors.deadletterqueue.topic.replication.factor": "3",
"errors.deadletterqueue.topic.name": "dlq_kafka_connect",
"errors.deadletterqueue.context.headers.enable": "true",
"behavior.on.malformed.documents": "warn",
"drop.invalid.message": "true",
Future tasks
A solution to synchronize data between MySQL and Kafka begs to be improved. For example, we could get rid of the Ruby scripts by leveraging the Change Data Capture (CDC). The stream changes directly from MySQL to Kafka using another Kafka Connect connector called Debezium.
Running Elasticsearch, Kafka, and Kafka Connect, etc. on the workstation requires a lot of CPU and RAM and the Kafka Connect is the most resource intensive of the bunch. Resource consumption gets problematic when the components are run on a MacBook in Docker containers: the battery drains fast, machine runs hot, fans get loud, etc. To mitigate the situation we will try to run Kafka Connect compiled to the native-image using GraalVM.
Wrapping Up
As of now, the data indexing pipeline is one of the most boring and least problematic parts of the search stack at Vinted. And it should be. The reliability and scalability of the Kafka Connect allows our engineers to be agile and focus on working on Vinted’s mission of making second-hand fashion first choice.
Footnotes
-
We also use Kafka REST Proxy and, unfortunately, headers with failure details can’t be fetched through it because Kafka REST Proxy does not support Record headers. ↩
-
For detailed description of the settings consult the documentation here and here ↩