Vinted Search Scaling Chapter 2: Routing Elasticsearch Requests with srouter
It began with Elasticsearch cluster upgrades. Every major Elasticsearch version brings new features, free performance, compatibility issues, and uncertainty. In addition, we had an itch to dissect requests, conjoin request with a response for analysis, record queries for stress testing, and account for each request per second. With these requirements in mind, we have built a sidecar component next to primary application.
The leftmost component is the core application that is not aware that search requests are being handled by multiple Elasticsearch clusters. Next component is sidecar service written in Rust programming language, we call srouter.
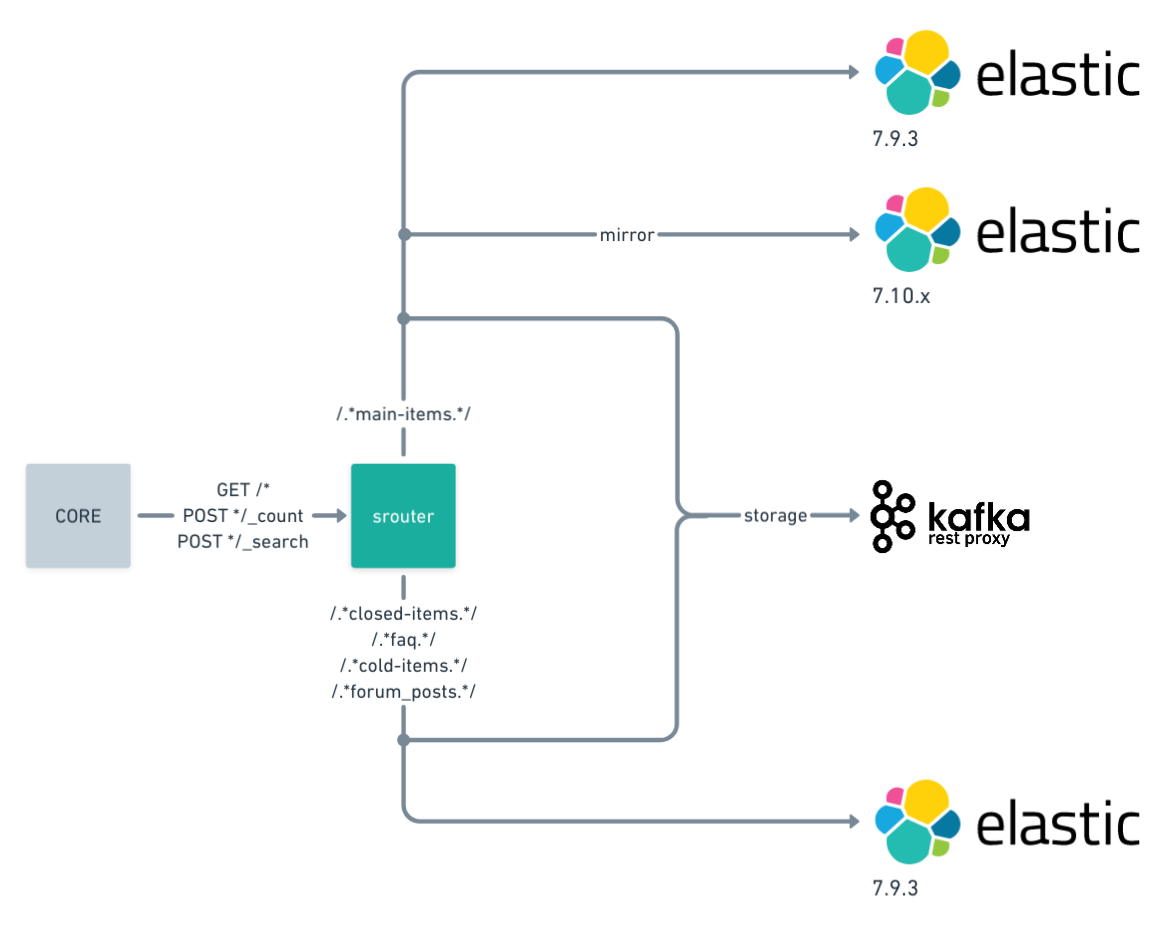
Srouter sidecar provides us fine-grained control of routing search requests to multiple Elasticsearch clusters which allows us to test and compare different Elasticsearch versions using the real-time production workload without impacting the production. Service is configured in a simple and readable way, configuration may be granular up to the specific HTTP request path, or greedy as required by the use case. A simplified configuration sample can be viewed below.
---
whitelist_ends_with:
- /_count
- /_search
routes:
main-items/_search:
main:
- http://127.0.0.1:1000
mirror:
- http://127.0.0.1:1010
amplify: 4
timeout: 311
lt-main-items/_count:
main:
- http://127.0.0.1:1100
timeout: 100
sampling: 10
storage:
- http://dc1-host.example.com:8082/topics/storage
default:
main:
- http://127.0.0.1:2000
timeout: 200
At the time of writing in production, we have defined 10 custom routes, it takes up to 3minutes to change any route in production, most of the time is spent in deployment.
Configuration is kept in a git repository to keep track of changes. In the configuration sample, we have greedy main-items/_search route with mirror traffic amplified 4x times.
Second lt-main-items/_count route has a timeout of 100ms and 10 percents of requests are sampled to Kafka.
Unmatched routes fall-back to default route. Srouter is picky about the HTTP method used, service allows any path HTTP GET requests, while HTTP POST requests are white-listed, in any other case service returns 405: method not allowed status.
The HTTP method limits protect from accidental index removal, direct indexing and serves as a gateway for engineers to “safely” access Elasticsearch.
Configuration flexibility unlocks imagination to tame search scale by shaping Elasticsearch clusters dedicated to handling specific types of requests.
Configuration routes are updated seamlessly without service interruption using SIGHUP signal. After receiving update signal, update is accomplished by using atomic pointer to update new routes. An atomic pointer is synchronized by relaxed memory ordering to point to new updated HashMap of routes. Srouter is OSI layer 7 router built on top of low level hyper server and tokio asynchronous runtime. As Rust is famous for performance this service is no different, it can provide more than 500k requests per second with 200 route updates every 10ms. Srouter single instance production resources footprint is 1 tokio core thread per 1 CPU with a total 124 megabytes of virtual memory, a large part of the memory (97%) is used by Prometheus metrics service exposes.
Metrics provided by the service are labeled per request path. Centralization of labeling in sidecar service makes a primary application simpler. Labeled metrics provides a base understanding of the frequency and volume of the queries, it helps to detect bad requests before production, measure each request percentile, track an exact number of requests. In addition to metrics, we are sampling a portion of queries and all unsuccessful responses. Sampled requests are enriched with requests, response headers, service time it took for srouter to complete the request and Elasticsearch response. Stored request/response combination allowed us to deprecate Elasticsearch slow query logs, the change reduced I/O activity, population sample of queries is improved. Population sample of queries is improved by sampling not only “slow” (where slow is defined by internal ES measure which depends on many factors such as search request queuing, indexing load, GC, etc) queries but also fast and even failed queries again in an uniform way.
Srouter proved to be a critical service to our planned scaling strategy. Anthony Williams in C++ Concurrency in Action[1] defines scalability as “reducing the time it takes to perform an action (reduce time) or increasing the amount of data that can be processed in a given time (increase throughput) as more processors are added.” We have summarized this in two simple scaling cubes.
Future chapters will explore how we are using “scaling cubes” to scale Elasticsearch. Liked what you have read? We’re currently hiring Search Engineers, find out more here.
Reference:
- [1] C++ Concurrency in Action by Anthony Williams, https://www.manning.com/books/c-plus-plus-concurrency-in-action
- Hands-On Concurrency with Rust: Confidently build memory-safe, parallel, and efficient software in Rust by Brian L. Troutwine https://www.amazon.com/Hands-Concurrency-Rust-Confidently-memory-safe/dp/1788399978
- Tokio https://github.com/tokio-rs/tokio
- Hyper https://hyper.rs, https://github.com/hyperium/hyper
- Scaling cubes: https://en.wikipedia.org/wiki/Scale_cube
- Greedy regular expressions: https://www.regular-expressions.info/repeat.html