Automating DNS organisation-wide
Managing DNS infrastructure at scale comes with its challenges.
Sometimes, when infrastructure expands, things that worked fine for years can start to become an inconvenience, or even blockers. It’s also possible that human error can cause service downtimes.
In this post, we will share with you our approach to automate DNS services inside datacenters, and the solution we took to eliminate the possibility of human error when configuring DNS services.
Managing split horizon DNS in a datacenter
“I'll tell you a DNS joke but be advised, it could take up to 24 hours for everyone to get it.”
- Internet
For years at Vinted, we managed to get by without an internal DNS solution, and all internal hostnames were resolved via good old hosts files. This meant that each host had to generate a list of all hostnames and their IP addresses to be able to resolve server names inside a datacenter (DC). While this solution had mostly worked for quite a long time, it had its drawbacks.
For example, one drawback was that when a new server was added (or removed), it took a significant amount of time for all the servers in a datacenter to update their hosts file. This meant that we ended up in some kind of split-brain situation for several hours where parts of servers were already resolving new hostnames, while other parts were not (because they hadn’t as yet been updated). Most of the time this wasn’t a real cause for concern, but it was a bit annoying when deploying new servers.
Another problem lay with updating the hosts file. We ran a chef ecosystem in our datacenters, and all hosts file updates were done by a chef-client. This led to situations where a server with a disabled chef-client could not find any recently added servers. Disabled chef-clients are not a frequent occurrence, but still, when it happened, it meant that we had an inconsistent configuration across datacentres. As our infrastructure started to grow, this solution became even more problematic because it didn’t scale well enough: each server had to get a list of all the servers in every datacenter via the chef-server, and generate hosts files out of them. It then came to the point where we needed to move out from a static file to a dynamic DNS solution. A problem occurred right in the beginning. We were using the same root domain name both for internal hosts and to provide external domain names served by a cloud DNS provider. With the hosts file solution this worked fine, because when an address was not found inside the hosts file it was queried against DNS servers. This was not an option while using DNS-only queries, as we didn’t want to serve our internal hostnames via an external DNS provider. To solve this, we could create a new zone for internal names. However, that implied that we needed to change hostnames for our entire server farm – also not an option. We needed a so-called ‘split horizon’ solution, where all DNS queries from inside datacenters would return different results than the direct queries to an external DNS. This is where a RPZ (or Response Policy Zone) comes in handy. What a RPZ zone does is rewrite the responses from an authoritative DNS with their own records. A solution with an internal RPZ zone would look like this:
Each server updates its hostname in the internal DNS RPZ zone, and uses the internal DNS as a resolver. Each response from an authoritative server to an internal DNS will be validated, and if needed (if the RPZ zone contains a required entry), responses will be overwritten by the RPZ zone entry. If there is nothing to be overwritten, the DNS will act as a simple DNS resolver, thus returning a result from authoritative DNS without rewriting it.
This solved all of the problems described above: there was no need to generate a list of all the servers on each machine, new hosts appear in DNS as soon as they are provisioned, and there is no need to run chef-client on each server to get updates about new machines. There also is a need to delete DNS entries about servers that are removed from the datacentre. Currently, the source of truth about all existing servers inside the datacentre is the Chef server, so we decided to run a periodic check against the RPZ zone and Chef inventory, and delete those entries which were not present.
We are using dnsmasq on each server as a DNS query router: all DNS queries are offloaded to secondary DNS servers unless they are consul queries, and consul queries are routed to consul servers. Dnsmasq also solves another problem – if one of the DNS servers is down it marks it as down, and it is not used until it is available again. Using a ‘resolv.conf’ file does not have this feature; it also always queries the first DNS server, so you end up in slow queries when the first server is down. You could use the ‘options rotate’ parameter here to make round-robin DNS queries, but you would still end up with random queries to a dead server.
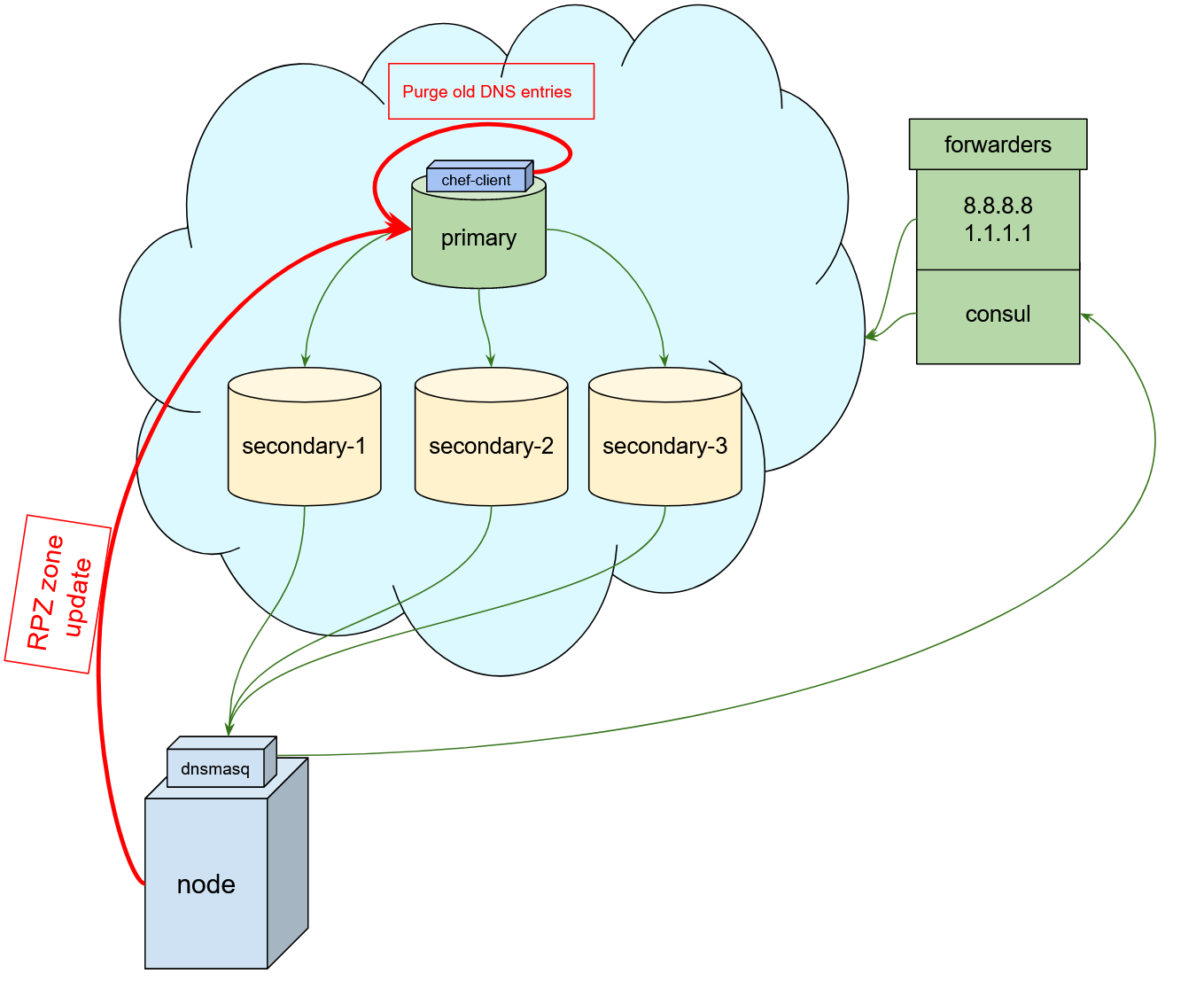
The picture above shows the solution we ended up with. Each node updates its hostname via ‘nsupdate’ calls to the primary DNS server. Secondary servers pull down all DNS updates from the primary server. Nodes use secondary servers to do all DNS queries (except consul ones).
DNS as code
“At the source of every error which is blamed on the computer, you will find at least two human errors, one of which is the error of blaming it on the computer.”
- Tom Gilb
There was a second problem we wanted to solve: how to reduce human errors caused while managing our external DNS (all DNS entries that are available to the public).
In the beginning, DNS entries were managed manually via our DNS provider control interface, but this process had many drawbacks:
- The chances of misconfiguration were high because there were no tests or review process on a configuration change;
- The audit log was unreadable and in many cases insufficient;
- There was no reliable change revert procedure;
- There was no clear way to initiate a DNS change if a person had no access to the configuration dashboard;
- In case of service provider outage we had no defined process how to move quickly all DNS configuration to another provider.
To address these issues we decided to go with a DNS as a code solution:
- Every change against external DNS should be done by Pull Requests via DNS repository;
- All changes should be automatically tested;
- All changes should be approved by several code owners of DNS repository;
- A tested and approved pull request should be rolled out to production upon merging it to the main branch;
- DNS configuration should be DNS provider agnostic if we decide to change one.
After some research we decided to go with a ‘dnscontrol’ toolkit, because it covered all requirements described above. It provided:
- syntax tests;
- dry run tests;
- the capability to use the same configuration for most DNS providers.
‘dnscontrol’ uses JS as its configuration language. If needed, you can therefore use JS code inside a configuration file to extend the DNS configuration. We have a separate configuration file for every DNS zone, which we import to the master config. After a while, we started to receive pull requests with a more sophisticated use of JS syntax – parts of configuration were defined as JS variables and reused in several places, thus making the DNS configuration even more robust and less prone to error.
When a new pull request is created, our CI/CD (Jenkins) runs tests against that pull request and comments on what changes will be done to the DNS upon merging.
When a pull request is approved by multiple team members, it can be merged to the main branch. Upon merging, Jenkins again runs tests, just to make sure nothing will break. Changes are then pushed to the DNS provider.
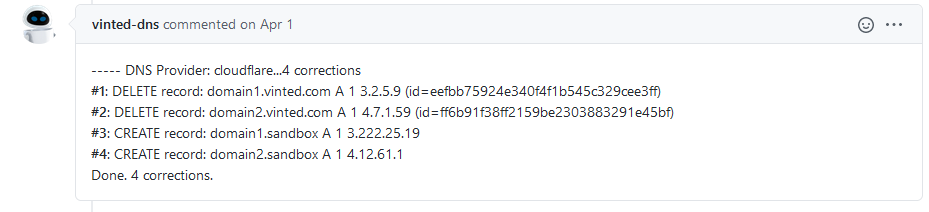
The picture above shows Jenkins commenting on a PR with multiple changes against a vinted.com domain.
In conclusion, DNS automation via ‘dnscontrol’ is a simple and convenient tool that you can use to build a robust DNS-as-a-code solution.