Vinted Search Scaling Chapter 5: Divide and Conquer
Elasticsearch is really fast out of the box, but it doesn’t know your data model or access patterns. It’s no secret that Elasticsearch powers our catalogue, but with the ever-increasing amount of listings and queries, we’ve had a number of problems to solve.
In the middle of 2020, we noticed an increasing amount of failing search requests during peak hours. Looking at node-exporter metrics in Grafana indicated nothing was really wrong and that the cluster load was fairly balanced, but it clearly wasn’t. Only after logging to the actual servers did we realise that the load distribution was uneven across all the Elasticsearch nodes we ran there.
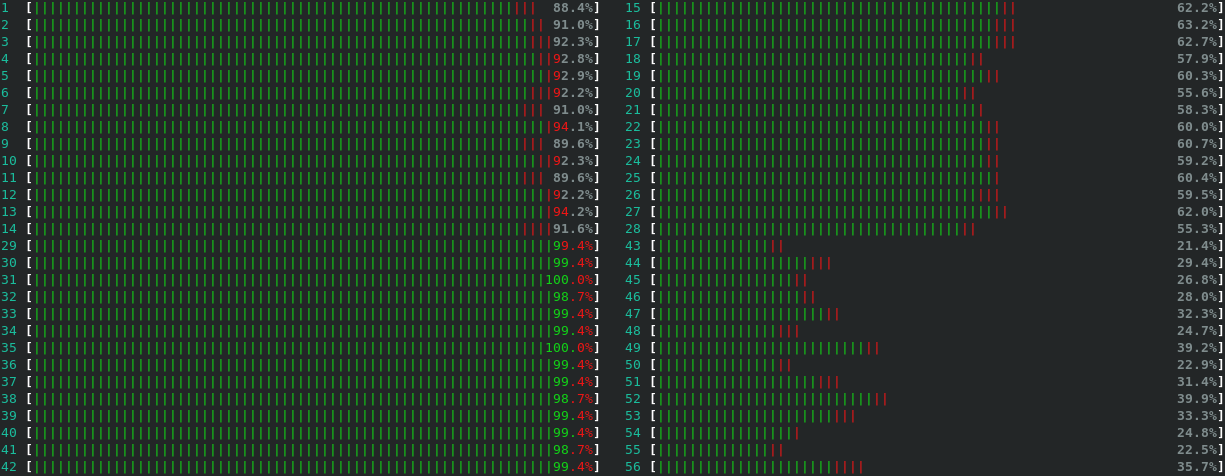
Following documented guidelines for optimizing cluster and JVM settings, we experimented with shard sizes and the number of replicas while following the number_of_shards * (number_of_replicas + 1) < #data_nodes recommendation. But this gave us no significant improvements, so we had to approach the issue with a different strategy.
We’ve decided to apply the ‘divide and conquer’ strategy by creating separate indices for specific types of queries. These could exist in a different cluster, have different numbers of shards or replicas, or different index-time sorting. We started by redirecting all of our /_count queries to another cluster, which significantly reduced the portion of failing requests. We then realized that we’ve discovered something important:
Vinted supports multilingual search and uses an index per language strategy. We also allow users to browse our catalogue by applying filters without requiring any search text. We’ve created a version of the listings index to support such kinds of queries. By doing that, we could put all of the listings into a single index, no longer analyse textual fields and redirect all browsing queries to them.
Surprisingly, it helped to distribute cluster load more evenly despite the fact that the new indices were in the same cluster. The extra disk space and increased complexity was a worthy tradeoff. We decided to go even further and partition this index by date to see if we can control data growth easier, improve query performance, and reduce refresh times. Splitting the index by date allowed us to leverage the shards skipping technique. For example, say search queries last for 2 weeks of data; Elasticsearch would optimise them by skipping shards, querying only the last month’s index partition and skipping the rest.
You may already know that we use Kafka Connect for our data ingestion and it comes with Single Message Transforms (SMTs), allowing us to transform messages as they flow through Connect. Two of these SMTs were particularly interesting:
Timestamp Router allows the construction of a new topic field using the record’s topic name and timestamp field with the ability to format it.
Regex Router allows updating the record’s topic using the configured regular expression and replacement string.
To use these routers, our records – and tombstone messages – must contain a fixed timestamp. Otherwise, we will never be able to ingest data to Elasticsearch consistently. By default, each new record is produced with the current timestamp, but ruby-kafka allows it to be overwritten with any value. We believed that overwriting it with the listing’s creation time would work. We also considered trying ILM and data streams but quickly rejected them, as both of these techniques target append-only data.
We built a small application that mimics our ingestion pipeline, but with a couple of changes:
- Overrides
create_timewith a fixed value for each key - Uses Timestamp Router to partition records into monthly partitions
{
"transforms": "TimestampRouter",
"transforms.TimestampRouter.timestamp.format": "yyyy.MM",
"transforms.TimestampRouter.topic.format": "${topic}-${timestamp}",
"transforms.TimestampRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter"
}
The config change is fairly simple but very powerful – it’ll suffix the record’s topic with the year and month using its timestamp.
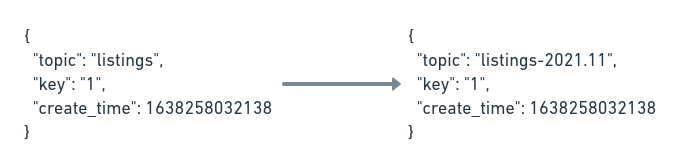
This is great, but we have lots of listings from the past, and creating a monthly bucket for very few records would be expensive. To combat this, we’ve used the Regex Router to put all the partitions up to 2019 into a single old one. It wouldn’t touch newer items.
{
"transforms": "TimestampRouter,MergeOldListings",
"transforms.TimestampRouter.timestamp.format": "yyyy.MM",
"transforms.TimestampRouter.topic.format": "${topic}-${timestamp}",
"transforms.TimestampRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.MergeOldListings.regex": "(?-mix:(.+)-((2010|2011|2012|2013|2014|2015|2016|2017|2018).*))",
"transforms.MergeOldListings.replacement": "$1-old",
"transforms.MergeOldListings.type": "org.apache.kafka.connect.transforms.RegexRouter"
}


After confirming this works as expected, we implemented this into our application, which was fairly simple:
- Create new topics for our listings (we don’t want to affect the current ingestion pipeline)
- Write to both old and new topics at the same time
- Use the listing to create time when sending records to the new topics
- Test ingestion with the new topics and routing strategy
- Switch to new topics once we confirm that ingestion works as expected
The initial switch to partitioned indices didn’t work out, so we’ve had to tailor our queries for them, tweak the number of shards and the number of replicas. After plenty of unsuccessful attempts, we finally have a version that works great.
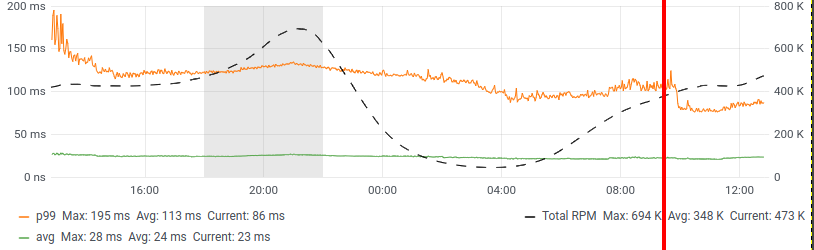
We’ve managed to not only shed 20ms off the P99 but have had other great results too:
- Query and request cache hit ratio is above 90% due to older indices refreshing less often
- Having load split between multiple indices results in a more even load across the whole cluster, so we no longer have hot nodes
- We’ve hit fewer index shards when querying for the top-k latest items
In retrospect, this abnormal behavior was most likely caused by bug in the Adaptive Replica Selection formula. But back in the day, we mitigated this bug by creatively applying the divide and conquer strategy, which helps us to this day.