Data Migration Project: Portal Merge
At Vinted, our long-term strategy is to build an international marketplace where users can trade between countries.
Initially, we had separate legal entities, core service instances and databases to serve our users in the countries we operate in.
We called them portals. For example, www.vinted.lt and www.kleiderkreisel.de were distinct portals.
To achieve our goal of building an international marketplace, we needed to merge them into a single entity.
This led us to solve several challenges here at Vinted engineering:
- How to create a seamless flow to help our users migrate
- How to migrate the data between our portals
Migrating data between our portals was an interesting engineering challenge.
In this post, I will share some details on how we did it and what we have learned.
Data migration solution
Abstract diagram
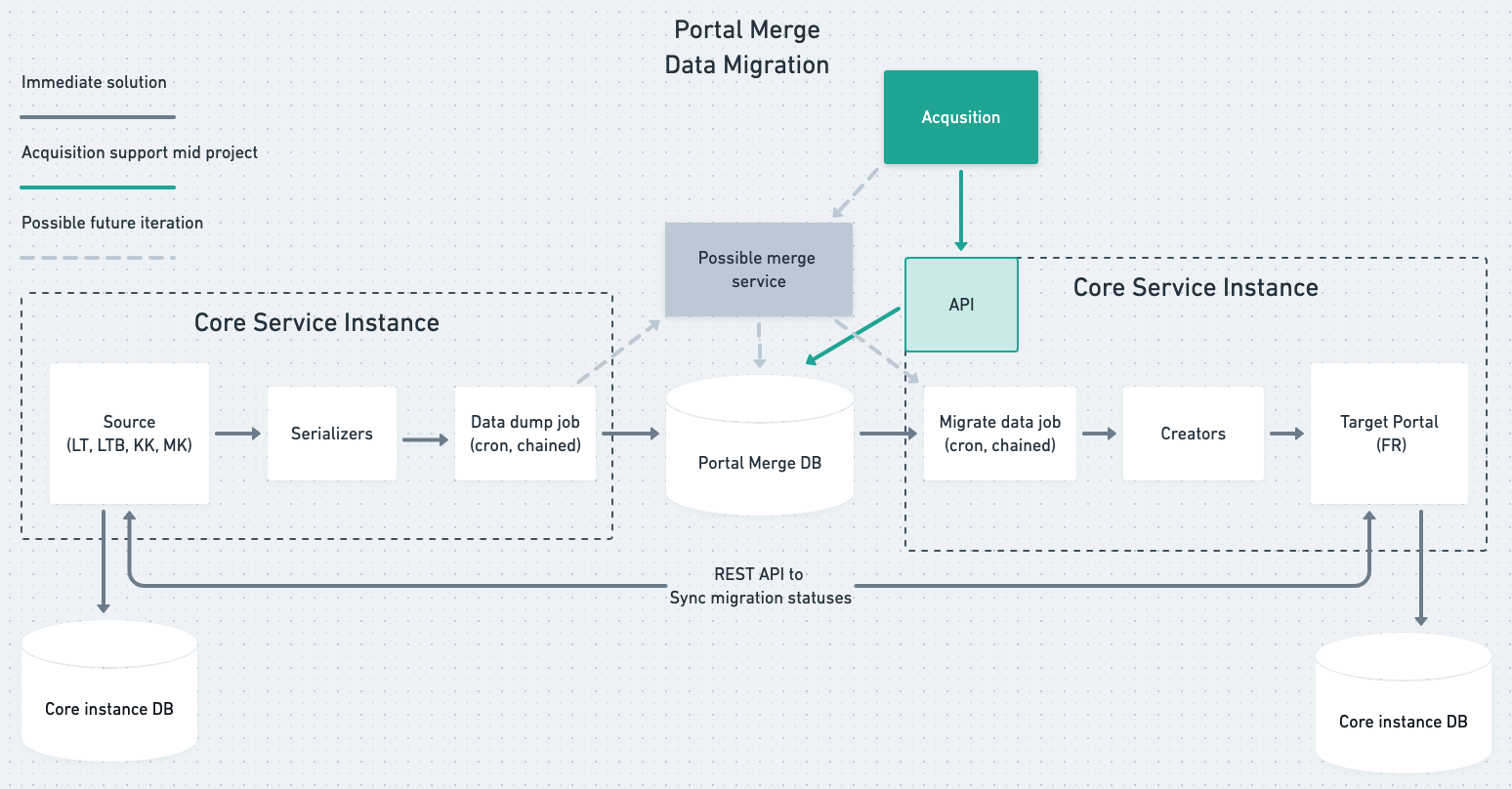
Figure 1
At its core, the data migration was a three-step process:
- Extract and serialise data from the source portal
- Push data to an intermediary database. We chose MySQL for this purpose. This was the job of the
Serializerclasses - Fetch data from the intermediary database, transform it and insert it into the target database. This was the job of the
Creatorclasses.
The Portal Merge Database is needed because:
- The migration happens asynchronously. Our background jobs fetch and insert data into it.
- It supports migration job retries. We track migration progress for every model being transferred.
- It’s a place to store ID mapping between source and target portals when migrating related data such as user followers, liked items and more.
- It stores other data related to the migration. This solves various edge cases, such as tracking sold migrated items, invalid migration records, etc.
Why solve these at the application layer?
Because our portals are operated as separate legal entities, we had to ask our users’ permission to migrate their data.
This is due to data privacy laws in the EU. Our users agreed to migrate all or certain parts of their data in a form like this:
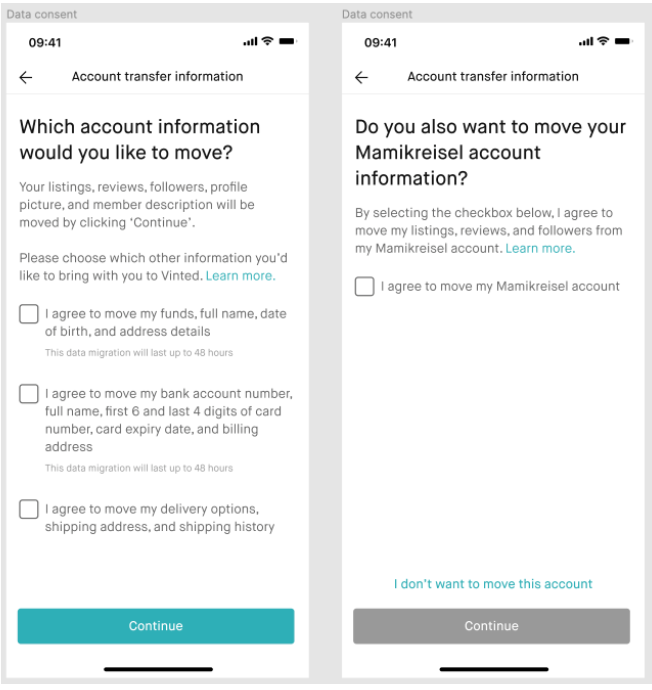
Figure 2
Migration states
nil. Default value. Meaningful in target portal until data serialisation has been completed.Pending. Migration object ready to be picked up by data serialisation job in the source portal and data migration job in the target portal.In progress. Respective job in progress.Completed. All user models are successfully transferred to the target portal database.Failed. After exhausting the retry limit, a migration is marked as failed.
Moving users between these states allowed us to track how well our system behaved.
Our system was also built to be re-entrant. That means we could run the migration as many times as needed.
In case of failures, we would move a user from Failed to Pending for a restart.
This field was also used to display feedback to our users.
Shared database
We chose to have a shared database between the portals because it was the simplest short-term approach. As code is shared between the instances, it saved us precious development time so we could get this solution to production as soon as possible. For example, we did not need to build an API and HTTP clients for fetching and posting data.
This tightly coupled our core service instances. It introduced a problem when migrating the database schema.
Multiple core instances would try to run migration scripts on the same database and crash.
To avoid this problem, we patched our migrations to run only on the target portal production and staging environments:
ActiveSupport.on_load(:active_record) do
if Rails.env.production?
module SharedDbPatch
def with_connection_of(model)
return if model.is_a?(SharedDbModel) && %i(target target_sandbox).exclude?(PORTAL_IDENTIFIER)
super
end
end
ActiveRecord::Migration.prepend(SharedDbPatch)
end
end
The control for accessing this database was placed on the migration statuses belonging to each core instance.
That meant the state transitions on both portals had to be free from errors.
Because the same migration status model was shared on both source and target portals, it was sometimes difficult to think about.
Acquisitions flow
In Figure 1. you can see a flow for supporting business acquisitions depicted by green lines. This was a possibility in our upcoming business development. Thus, being open to this possibility proved beneficial. Surprisingly, we had to develop this flow even sooner than expected.
Our initial design worked well for us here. To support this flow, we only had to extend the already-built migration system –
by building an API layer for inserting required data into the Portal Merge Database and adding the required Creators.
The Serializer part was covered by the acquired company.
Future iterations
If it makes sense to our business, the possibility to decouple source and target portals is always there. As depicted by the grey lines, we can create a service on top of the Portal Merge Database.
Lastly, all Vinted source portals will eventually get merged. Leaving us to only support the acquisitions flow. In such a case, making the Portal Merge Database yet another shard for our core. If it were too costly to build a separate service, we could also leave it in our monolith.
A company-wide initiative
This project was a company-wide initiative. Different models are maintained by different teams.
We needed to divide the work into teams with respective owners.
We created a division between the general migration logic and serialising and recreating individual records.
This allowed teams to independently add logic for migrating their respective models.
We built a configuration object where we defined:
- the model to be migrated. Defined by the key in snake_case
- a query scope to apply to model. f.e. to exclude draft items
- the type of user consent required
- whether it should be skipped in the portal.
MODELS = {
migrate_all_model: {},
scoped_model: {
query_limiter: lambda { |relation|
relation.where(external_type: nil)
}, # model with applied scope
},
consent_and_skip_model: {
consent_type: SHIPPING_CONSENT_CONSTANT,
skip_serialize: %i(example_portal_1 example_portal_2),
}, # model with consent requirement. To be skipped in LT
...
}
The object key was used to build the Serializer and Creator classes.
Because classes in Ruby are constants, we can write such statements:
serializer = "MergePackage::Serializers::#{model_type.to_s.camelize}".constantize
creator = "MergePackage::Creators::#{model_type.to_s.camelize}".constantize
This way, we don’t need to define the classes explicitly. Leaving us with a naming convention. Usually, I would be in favour of being explicit. But, we chose to follow the Ruby on Rails “convention over configuration” practice.
Controlling migration throughput
The data migration flow sends a lot of database query requests to services and runs many computations. Our portals serve a significant number of users, and all of them once enabled on a source portal, would need to go through this flow. So as not to overwhelm our system, we needed to limit the number of requests we processed at any given time.
For that purpose, we used the chained job library built here at Vinted. It allows us to limit how many jobs are run in parallel. This setting was exposed to be set on the fly. In this way, we could calibrate the system once we started running it in production.
Handling failures
Every part of the migration was built to be re-entrant. That means our jobs could fail and be retried as many times as needed, when:
- database requests fail
- service requests fail
- we get unexpected input that we fail to process. In this case, we mark the record as failed. And process them at a later stage once the issue is fixed.
When creating records on the target portal, we tracked our progress in the merge database while inserting the records in batches within database transactions.
In other parts, we had to make sure that the code could be run multiple times with the same result in other ways – solving it case by case.
Telemetry
We collected various metrics, such as:
- initiated and completed migrations
- single-user migration time start to finish
- processed record counts for individual models
- counts of communications sent out related to the portal merge
- and more
Gauging pending serialisation and data migration jobs was specifically useful. We could see whether we were keeping up with the influx of requests.
In turn, increasing the job parallelism until we found the right number for our infrastructure, where we don’t overwhelm our system and manage to keep up well with incoming migration requests.
Complexity
High and low throughput migrations
Our initial design included low and high throughput migration controls. That means we could migrate models at different paces. We set the pace by having different job parallelism and run frequency settings.
It was decided under the assumption that the overall migration time would be impactful to the user. To solve this, we prioritised some important data to be transferred faster than others.
After building and running the solution in production, we learned this assumption was wrong. We could easily run the migration at one speed.
In essence, we over-engineered by premature optimisation – a classic lesson in our field.
Vinted and Vinted for babies
The first portal merges happened in Lithuania and afterwards, Germany.
In Germany and Lithuania, we had two products: generic second-hand clothing trading and baby goods trading.
A good portion of our users had accounts on both platforms. To provide a good user experience, we built a flow to submit a migration on both portals with one form.
Naturally, this introduced additional complexity to our solution:
- to initiate migration with a single submit from either portal
- to mark the migration completed on the target portal only after both had been completed.
After completing merges in these countries, we easily removed this logic.
Other cases
Additional complexity was also added to solve:
- data that did not belong to users directly
- forum migration. We wanted all of its contents to be migrated immediately
- other edge cases related to payment data and more
Testing
Automated end-to-end tests for the data migration tool proved invaluable. They would initiate a migration via API and test the output generated on the target portal. They helped us catch issues that we could not catch with our unit and integration tests.
After thorough QA testing rounds, we also did “swarm testing” in Lithuania with Vinted employees:
- we got unexpected data as input – data which should seemingly not be allowed. But, it existed due to the long history and evolution of Vinted’s source code
- we found additional bugs in our user journey – related to unexpected data and inputs that we did not yet cover in our testing.
For additional safety, we first launched in our smallest market, Lithuania.
We also scaled the migration to our users gradually by control of our feature switches, which allowed us to enable migration to a % of the user base.
We also sent our communications related to the portal merge in rounds. Every time we sent a communications batch – we saw a spike in incoming requests.
All these steps allowed us to fix issues along the way – providing our users with a quality experience.
Conclusion
Vinted has been in production for over 10 years, and we have a significant amount of user data.
The system is live and we wanted to provide a seamless experience to our users without downtime.
These reasons, among many others, made this project a really interesting challenge.
I summarised the approaches we took – what worked and didn’t. However, a lot of details have been left out in favour of brevity.
To ensure a timely, high-quality release, it was imperative to:
- look for the simplest solutions possible
- take approaches that could scale well throughout the organisation so multiple teams could develop and make decisions autonomously
- be open and ready for the unexpected. New edge cases to cover constantly came up, and our designs had to be open to that.
To our delight, the project was a success. My hope is you’ve learned something valuable as well.
Take care!