Vinted Search Scaling Chapter 7: Rebuilding search indexing pipeline
Building an effective and efficient data ingestion pipeline is a challenging task. Let’s cover the migration from scheduled Sidekiq background jobs to real-time indexing built using Apache Flink.
Until recently, all the searchable data was fed to Elasticsearch using delta jobs. The model was simple, whenever a searchable entity changes, Rails hooks would bump its updated_at value and the delta indexing job would pick it up. We could control the job frequency to have a fine balance between system load and event lateness. We would update our items every 7 minutes, meaning that whenever members upload something to our catalog, they would have to wait up to 7 minutes for their changes to be visible in the app, which was not ideal.
When a new important field would be introduced to searchable entities, we would have to schedule a separate job to backfill the data. Backfilling our catalog would take a week and hog a large portion of the Sidekiq resources. This was a major bottleneck because it would discourage experimentation and new feature development, reindexing would simply take too much time and would be hard to iterate on.
Luckily, our Data platform team had completed the change data capture (CDC) implementation, which we had anticipated for a long time. With streaming data, we could react to changes in near real-time without putting any extra pressure on the database. This also means that we have to completely rearchitect the way our indexing pipeline works.
We chose Apache Flink to do that for a very simple reason, our data platform team has already successfully adopted that and is really happy with it. To name a few things that Flink does exceptionally well:
- Built for streaming applications
- Rich operator suite
- Easy to scale
- Fault-tolerant
- An easy-to-use web interface
- Provides extensive metrics
Phase one
We started slowly by implementing streaming applications that are not complex and have very small or no state. This was a good exercise to onboard ourselves to application development with Flink and programming with Scala. We also could easily experiment with different Flink settings to see how much throughput we could get.
To measure things, we set up a Grafana dashboard with Flink metrics, we were interested in the Kafka throughput and application resource usage. Without knowing the exact numbers, it would be impossible to measure our work. On top of that, we extensively used flame graphs provided by Flink to look into job hot spots. This has not taken long due to the fact that the jobs we were migrating were relatively simple and had low throughput.
Phase two
After becoming more comfortable with Flink, we rolled our sleeves up and started working on item search migration. We started with housekeeping, there were lots of deprecated and no longer used features, so we started by cleaning them up instead of blindly migrating them and potentially adding extra complexity that no one asked for.
Now this is a bit counterintuitive, but we decided not to use the Flink state for a couple of reasons:
- We expected the application state to become large, meaning that whenever we would want to redeploy the application, we would need to load it back to the job, this could easily take even half an hour, we could not allow ourselves such a downtime
- To construct an item document, we need to join a lot of streams, which would result in a lot of Flink expensive network shuffles.
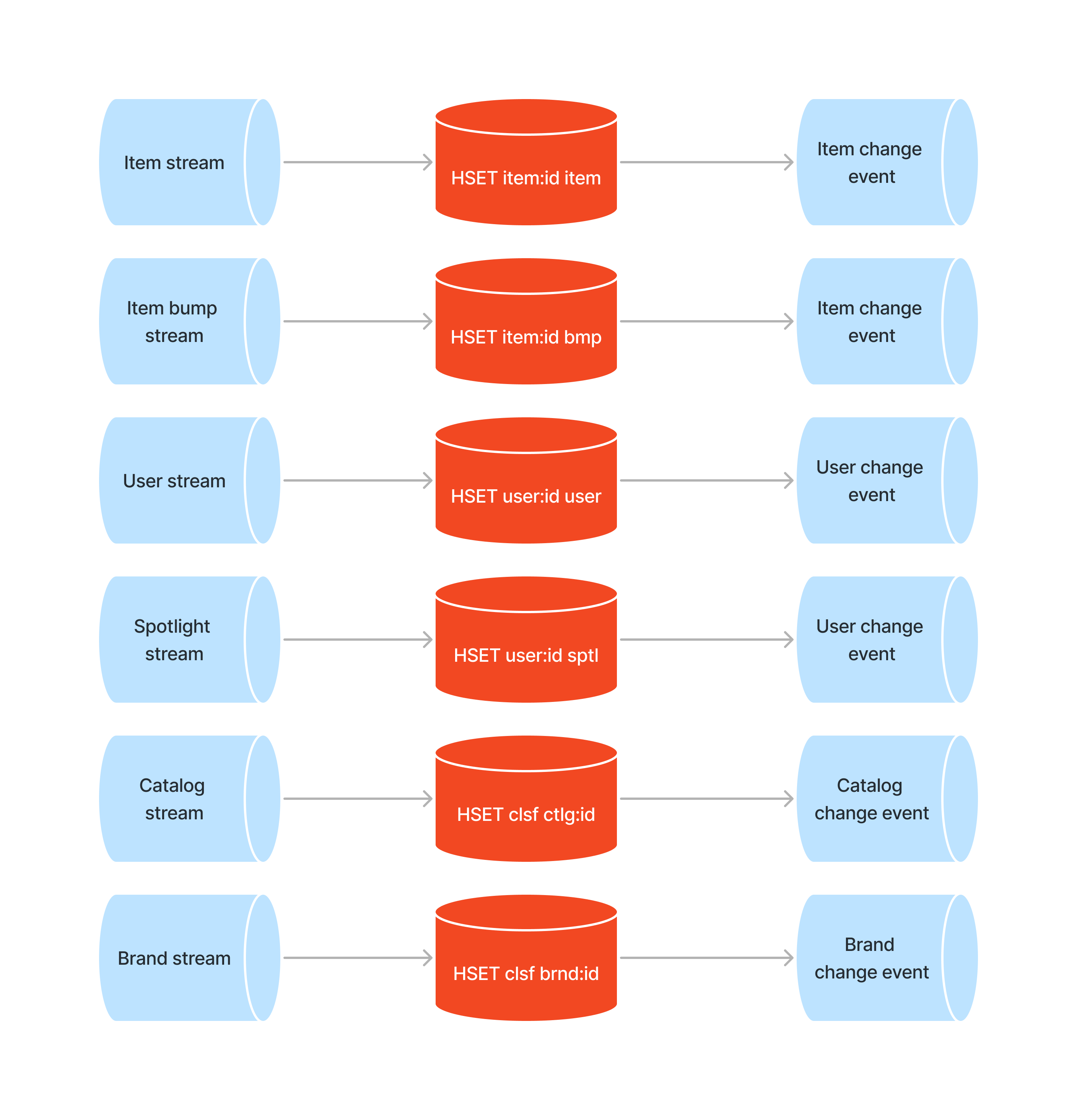
Instead, we opted for Redis as our state. Using Redis hashes, we were able to model data in such a way that it was enough to make 3 Redis calls to fetch everything needed to construct an item. One for the item, one for members, and one for the enrichments such as catalog, brand, and color details. We could do all of that in a single asynchronous operator and avoid network shuffle. Besides that, such a model was more familiar to other developers being onboarded to Flink and Scala, meaning they would be able to implement features themselves with very little support.
To implement that, we’ve deployed separate Flink jobs that would populate Redis state for us and emit a change event whenever it would update the state. We then could consume these events in other jobs and trigger actions whenever an event arrives. Each and every event would be a JSON-encoded record representing what was set or deleted from Redis, for instance a event representing an item bump could look like this:
{
"__deleted": false,
"id": 1,
"item_id": 2,
"bumped_until": "2023-10-25T08:15:27Z"
}
Phase three
The last most important jigsaw piece was data reindexing. We could not stop the existing application and redeploy it from scratch, this would result in items not being seen in the catalog for some time. We needed something better. After lots of workshops and procrastination, we had a light bulb moment. “Why not produce stream events representing a reindexing event and make it part of our organic stream?” We connected the organic item stream and the reindexing stream, and whenever we would receive an event to reindex an item, we would look its details up in Redis and forward it to the chain, items that would not exist in the Redis store would be skipped. With such a model, data reindexing becomes only a matter of publishing messages to a Kafka topic. The best thing was that with such a model we could plug any stream related to the organic one and trigger reindexing.
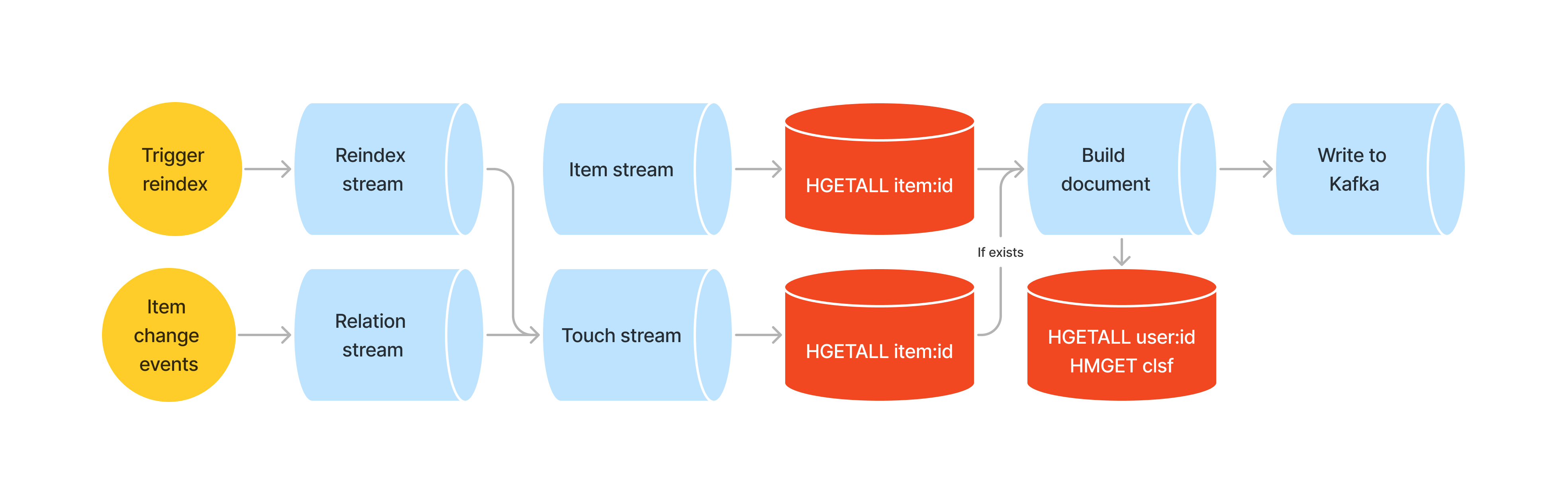
The reindexing events look as follows:
{
"offset_id": 0,
"batch_size": 1000
}
We would consume such events in one of the stream operators, expand that we want to reindex items with ids ranging from 0 to 1000.
To update items whenever there’s an item change event, we would pick only the item_id field from the change event and plug that into the same stream as with reindexing.
The hard parts
Having minimal experience with Redis, it was a challenge to model data efficiently. We started with regular key-value pairs and expected to fetch them using the MGET operation. The design was simple but would not scale well because it would have to query lots of Redis shards to get the results. Remodeling them as hashes with common keys allowed us to reduce the amount of network calls we made, which resulted in lower CPU and network usage.
Storing data as JSON is convenient but expensive. For large volumes of data, we switched to MessagePack, it was not as flexible as JSON and required implementing serialization and deserialization manually, but it resulted in much more compact storage and faster storage times.
Flink loves memory and gives all the knobs to control the way to use it. Our Redis client of choice (Lettuce) uses native transports, which means we had to allocate lots of off-heap memory. Otherwise, task managers would run out of memory and constantly restart. Flink can recover from these restarts easily, but this is costly.
Due to Flink’s distributed nature, everything Flink transfers between operators must be serializable. Sockets, connections, and others cannot be sent over the wire and must be reconstructed by every operator. The easiest way to do that is by carrying around serializable components required to do the initialization, such as connection strings. It is recommended to use rich operators and their open methods to do that, open method is called once before constructing the operator. This resulted in lots of open Redis connections even when they are thread-safe and it is recommended to use a single connection across the application.
We did use Flink’s state for smaller applications and changing the underlying schema can be tedious. You have to ensure that the underlying class is a POJO and one needs to use savepoints to be able to evolve the schema, regular checkpoints will break your application.
Flink upgrades are hard. The application and cluster versions must match. Whenever we upgrade the system, we have to temporarily stop all the streams, take their snapshots, and then redeploy them one by one. If the application state is large, this can take a lot of time.
Outcomes
The migration was difficult and required many design changes. We’ve remodeled data numerous times but the outcomes were totally worth that.
We can now process changes in near real-time and members can see their newly published items in our catalog within a minute.