Investigation: Identical Servers, Different Performance
Inconsistent Redis performance was observed across a fleet of otherwise identical servers. After investigation, we discovered that differences in Linux system clocksource settings - specifically, servers running the slower HPET clocksource instead of the default TSC - led to significant increases in Redis latency and CPU usage.
This post summarizes our findings, shows how to spot and fix the issue, and gives tips to prevent performance drops from unintended clocksource changes. Fixing this simple config can lead to immediate, measurable improvements in throughput and system efficiency.
TL;DR
- System performance drops, especially for high-throughput workloads, if the server switches from the default TSC clocksource to HPET.
- The kernel might fall back to HPET if TSC sync fails, often after the server is powered off for a long period.
- You can check and switch your available clocksource easily (see below).
Problem
Some “identical” servers were running slower, with increased latency and CPU usage. We needed to understand why.
What’s a Clocksource?
A clocksource is how the Linux kernel keeps track of time (“read the clock!”).
- TSC: Crazy fast, lives on modern CPUs.
- HPET: Accurate, but slow for frequent reads.
More technical details:
Investigation: What’s Going On?
🔎 We dug in and noticed a pattern:
- Slower servers were all using the HPET clocksource.
- Fast servers stuck with the default, TSC.
- By default, kernels prefer TSC, but will abandon it if synchronization issues are detected.
Example log snippet:
Apr 15 18:22:57 srv kernel: TSC synchronization [CPU#0 -> CPU#8]:
Apr 15 18:22:57 srv kernel: Measured 120 cycles TSC warp between CPUs, turning off TSC clock.
Apr 15 18:22:57 srv kernel: tsc: Marking TSC unstable due to check_tsc_sync_source failed
Why does this happen?
We’re not 100% sure. It could be hardware or firmware quirks, or the server being powered off for long periods.
Visual Evidence
System CPU Usage (TSC vs. HPET)
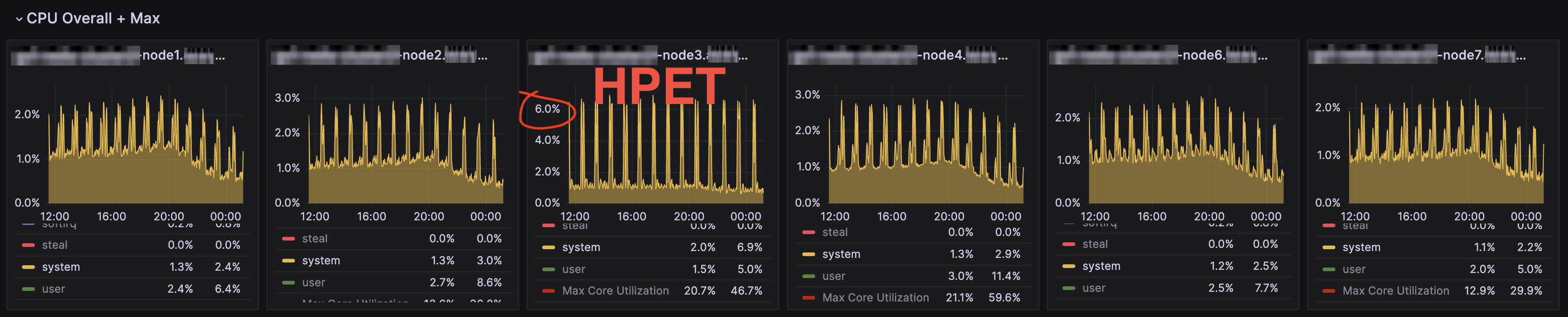
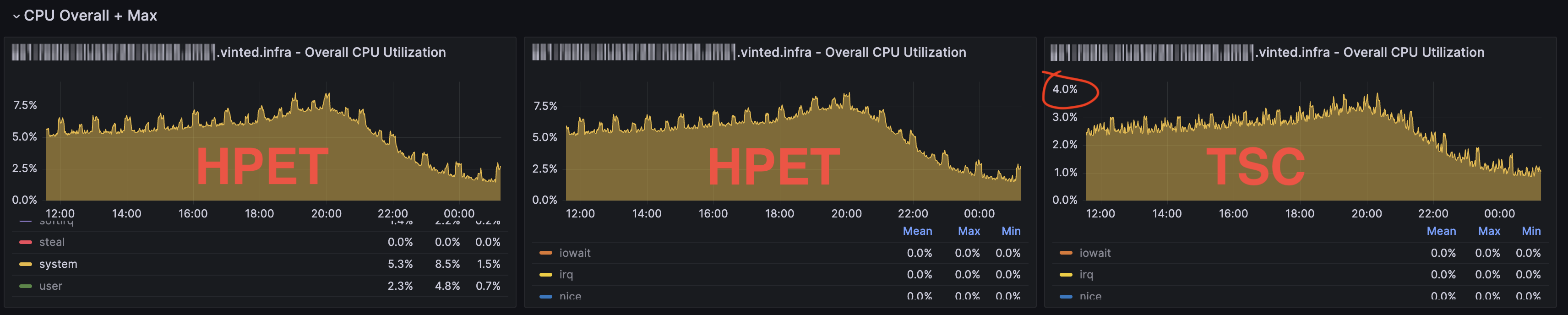
- CPU usage is significantly higher on HPET than TSC for the same workload.
Redis CPU/performance/rate
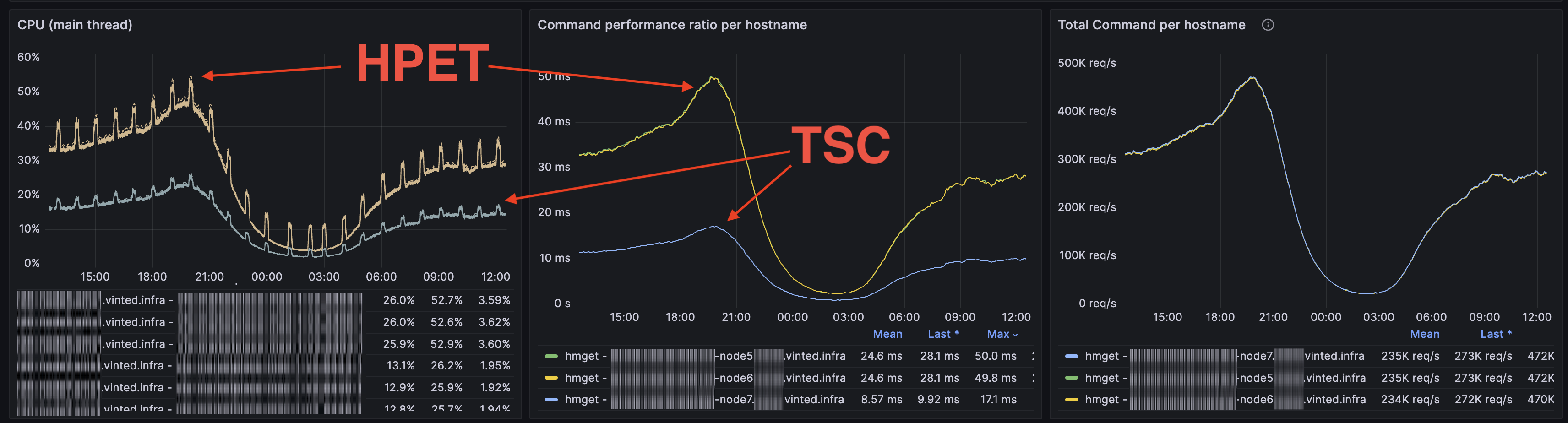

- Application latency and CPU usage spike when HPET is used.
Benchmark: The Pain is Real
Objective: How much does the clocksource really matter for high-throughput workloads? (Benchmarked via Envoy to Redis proxying.)
Test Setup
- Deployed Envoy proxies on two identical servers.
- Both routed requests to the same Redis cluster.
- Tests run in three phases to single out clocksource effects.
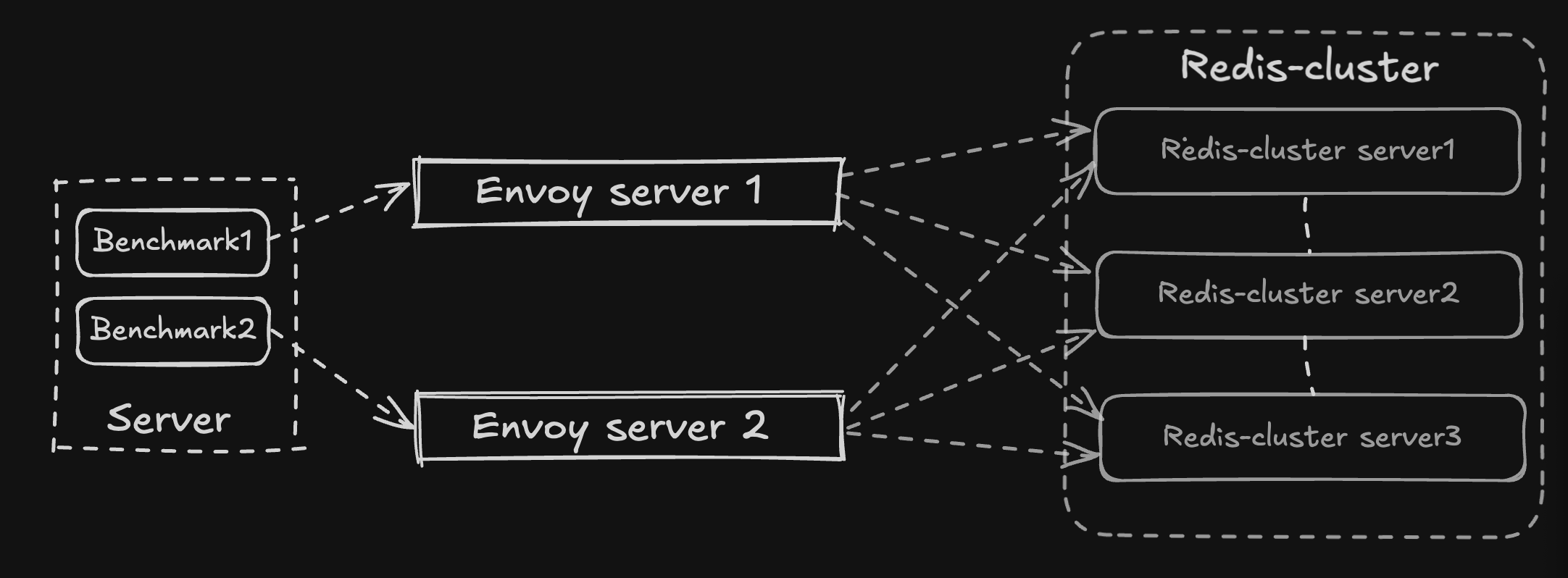
How the test was performed
On a dedicated server, we ran separate instances of a custom Go benchmark app: one aimed at each Envoy. These apps continuously sent SET and GET commands to Redis at a constant rate, while steadily increasing the number of goroutines at regular intervals, resulting in a steadily growing Redis command RPS over time.
Envoy’s Redis metrics were collected every 10 seconds using a standalone Prometheus server.
Benchmark Phases
- Baseline: Both servers on TSC.
- HPET on Server 1: Server 1 switches to HPET, Server 2 stays on TSC.
- HPET on Server 2: Swap: Server 2 on HPET, Server 1 on TSC.
Results
- Switching to HPET = instant slow-down.
- Increased CPU usage and application latency were very evident.
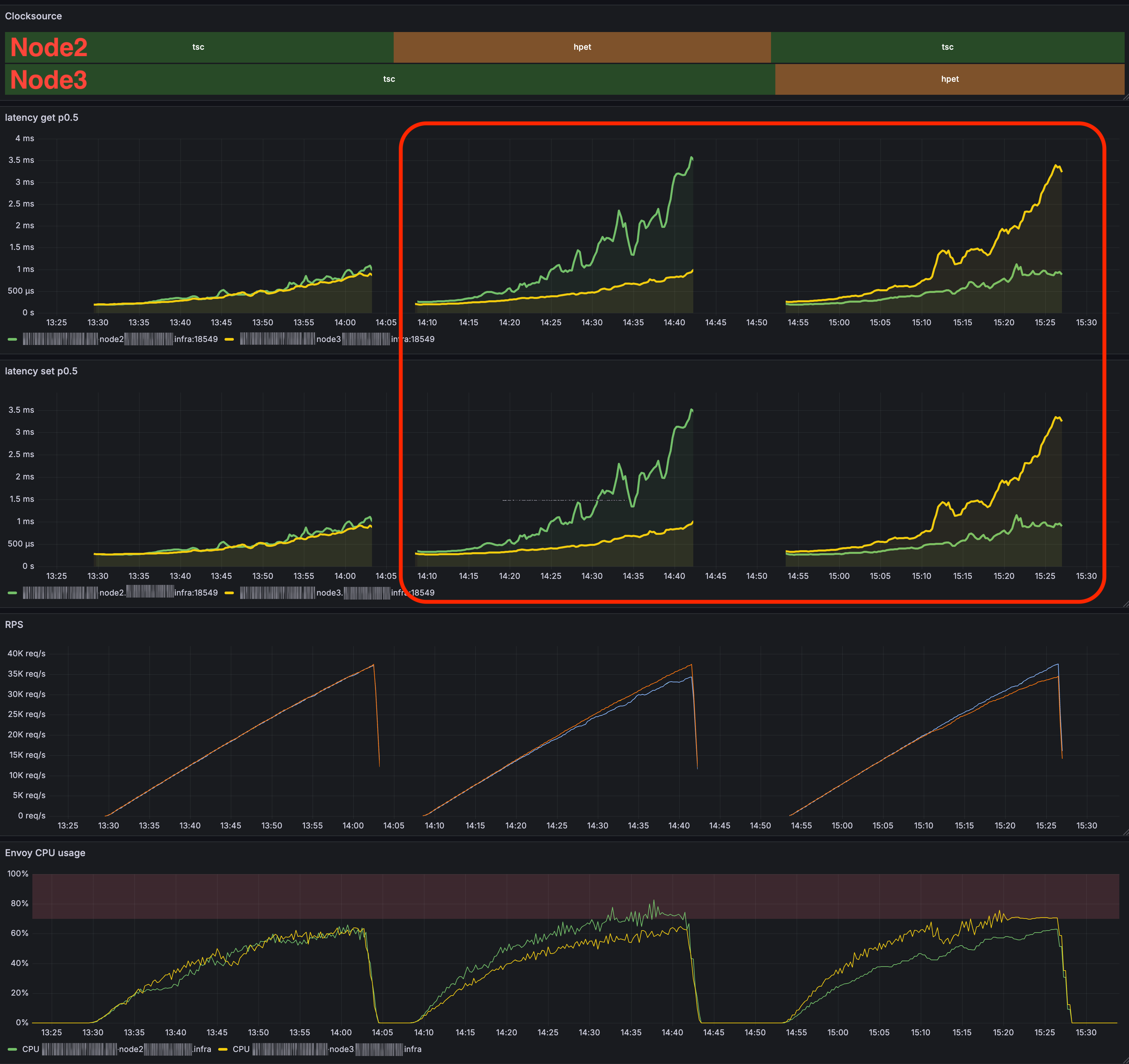
Conclusion
HPET = Performance Killer for High-Throughput Workloads. Stick with TSC whenever possible - otherwise, expect increased latency and higher CPU usage.
How to Reproduce (Or Fix) This
When does it happen?
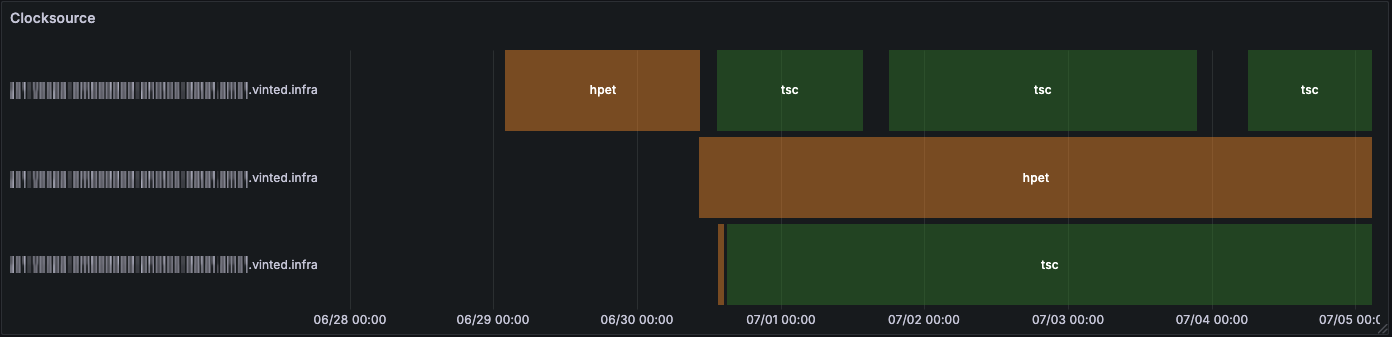
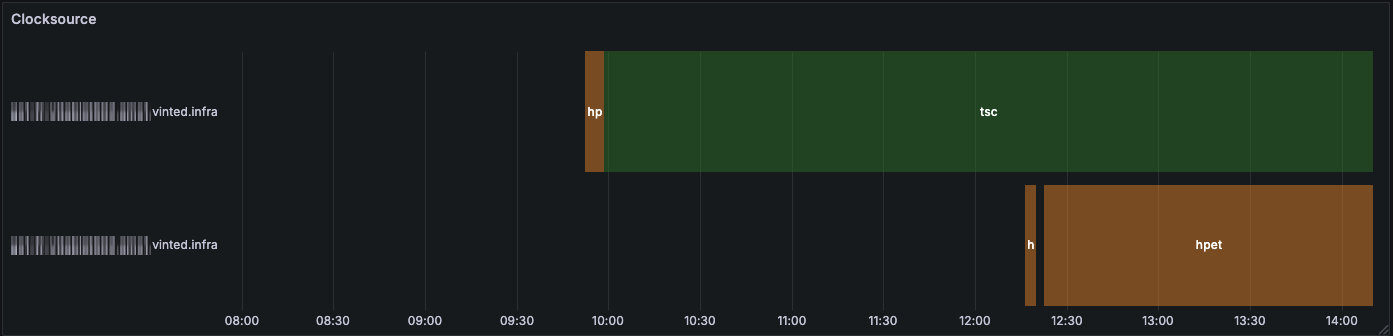
The following screenshots show a timeline of the selected clocksource. Periods with no color in a server’s timeline indicate that the server was offline.
- Servers left OFF for a long time sometimes boot with unstable TSC, so the kernel falls back to HPET:
- A simple reboot might fix it, but not always:
How to Check / Change Your Clocksource
# See available clocksources
cat /sys/devices/system/clocksource/clocksource0/available_clocksource
# See current clocksource
cat /sys/devices/system/clocksource/clocksource0/current_clocksource
# Change current clocksource
echo "tsc" | sudo tee /sys/devices/system/clocksource/clocksource0/current_clocksource
Key Takeaways
- Always check your clocksource if you notice unexplained performance drops.
- Prefer TSC for high-throughput or latency-sensitive workloads.
- A simple reboot or manual switch can restore performance.