Using Vitess in our CI/CD pipeline
Here at Vinted, we adhere to the continuous deployment principle, meaning that each merge to the main branch of the code repository initiates an automatic deployment process. As a result, the merged code goes live in a short period of time. Merge small and merge often are two practices that are instrumental to our day-to-day engineering work.
This approach mitigates friction when working on a shared code base, shortens the feedback loop, and reduces the anxiety of breaking the production environment with a gigantic change. But for it to actually work, one must have very good code test coverage, deployment automation tools with solid safeguards in place, a reliable observability stack to catch problems in the deployed products, battle-tested rollback, recovery procedures, and much more.
In this post I’ll touch on the testing phase. Specifically, I’m going to explain how we make use of the Vitess database to run backend tests of our core application.
I assume that you’re already somewhat familiar with Ruby on Rails, RSpec, Vitess, and Kubernetes. If not, then I would suggest spending some time getting acquainted with them first, as I’ll jump right into some details about them below.
Tests - then and now
Vinted Marketplace is one of the biggest and most important products created in Vinted. Under the hood of this online platform there’s a Ruby on Rails application called core. It was the very first Vinted application that was migrated from ProxySQL to Vitess. Here’s a series of posts by my colleague Vilius on our journey to Vitess that you should definitely check out: Vinted Vitess Voyage: Chapter 1 - Autumn is coming.
At the time of writing this post, core has more than 30 keyspaces (logical databases), with critical ones horizontally sharded or in the process of sharding. VTGates serve 1.3 mln. queries per second during peak hours, and data size is around 15 TB.
As described in the introduction, core is deployed continuously, with around 150 pull request builds and 50 main branch builds (that eventually end up with code release to production) per average working day. During each build, backend tests are executed by running 30,000 RSpec examples. It’s worth mentioning that the database is usually not mocked out, therefore tests execute actual SQL queries on a running MySQL server.
Our CI/CD pipeline is driven by the good old Jenkins with a fleet of agent nodes. For a very long time, specs used a MySQL server running directly on the agent server. This made setup super easy, and prevented additional latency and possible transient failures due to the network layer. The sheer number of examples that needed to be run meant that we started using the parallel_tests Gem a long time ago. With around 10 parallel runners, we were able to keep the duration of the backend tests stage under 15 minutes, which we considered acceptable.
Once we started migrating core from ProxySQL to Vitess, we had to decide what to do with the tests. Essentially, the question was if we trusted Vitess’ claim of MySQL compatibility to keep running tests on plain MySQL. In the end, we did. Our experience confirmed that it was the right choice. Granted, we had some nasty Vitess-related surprises, but these were usually caused by various configuration issues, and not an unexpected (untested) database query behaviour.
Then came the moment when we started preparing for the first horizontal sharding. Now this was going to be a bit more challenging. Vitess horizontal sharding has no direct analogue in plain MySQL, and it introduces a number of new limitations. For example, such an innocent looking call as User.first would fail if the underlying users table was sharded. Keep in mind that this was way before the query_constraints feature was introduced in Rails.
We decided that we needed to be able to run tests on Vitess. It was helpful that we were only going to horizontally shard a single table. The potential impact of releasing an unsupported or incorrectly working query to production was quite limited. That’s why we picked the middle road - to only run a limited subset of specs on Vitess in parallel to running all of them on plain MySQL as before. We were well aware that this was risky, error prone, and would not scale in the future. But kicking the can down the road is a legitimate tactical decision in certain cases. It allowed us to concentrate on more important tasks at the time, while reducing the risk to an acceptable level.
The final design was a simple one. We added a parallel Jenkins Pipeline step that started a Vitess cluster in a Docker container on the agent, loaded DB schema, and ran some predefined specs. RSpec tagging functionality was really handy here:
RSpec.describe <TestedThing>, vitess: true do
...
end
and
bundle exec rspec --tag vitess
This setup worked well for us for around six months. But then another “Vinted Autumn” came and we were once again struggling with an ever increasing load. It was more than clear that we needed to horizontally shard many more tables, and we needed to do that as soon as possible. This also meant that running only a subset of specs on Vitess was no longer a viable option, so we needed to up our game.
At that point we toyed with two main ideas: run all backend tests on Vitess or run tests on plain MySQL and analyse (explain) the produced queries somewhere on the side. We were leaning towards the first option, but had some obstacles to overcome. Simply put, we needed tests on Vitess to run comparably fast to tests on agent-local MySQL servers. At that point in time, we were quite far from this goal.
Luckily, in the end, we managed to find solutions to all major challenges. We’re currently running all core backend tests on Vitess with each pull request build. Vitess used for tests reflects the production setup as close as is needed in this scope. Most importantly, code that runs on horizontally sharded keyspaces in production, runs on horizontally sharded keyspaces in tests too. This does not guarantee that unsupported query won’t sneak into production as there’s a chance that some code paths are not fully tested. But the chances of this happening are greatly reduced.
Below is the general overview of our tests’ setup. And in the following chapters I’ll give you more details on specific elements.
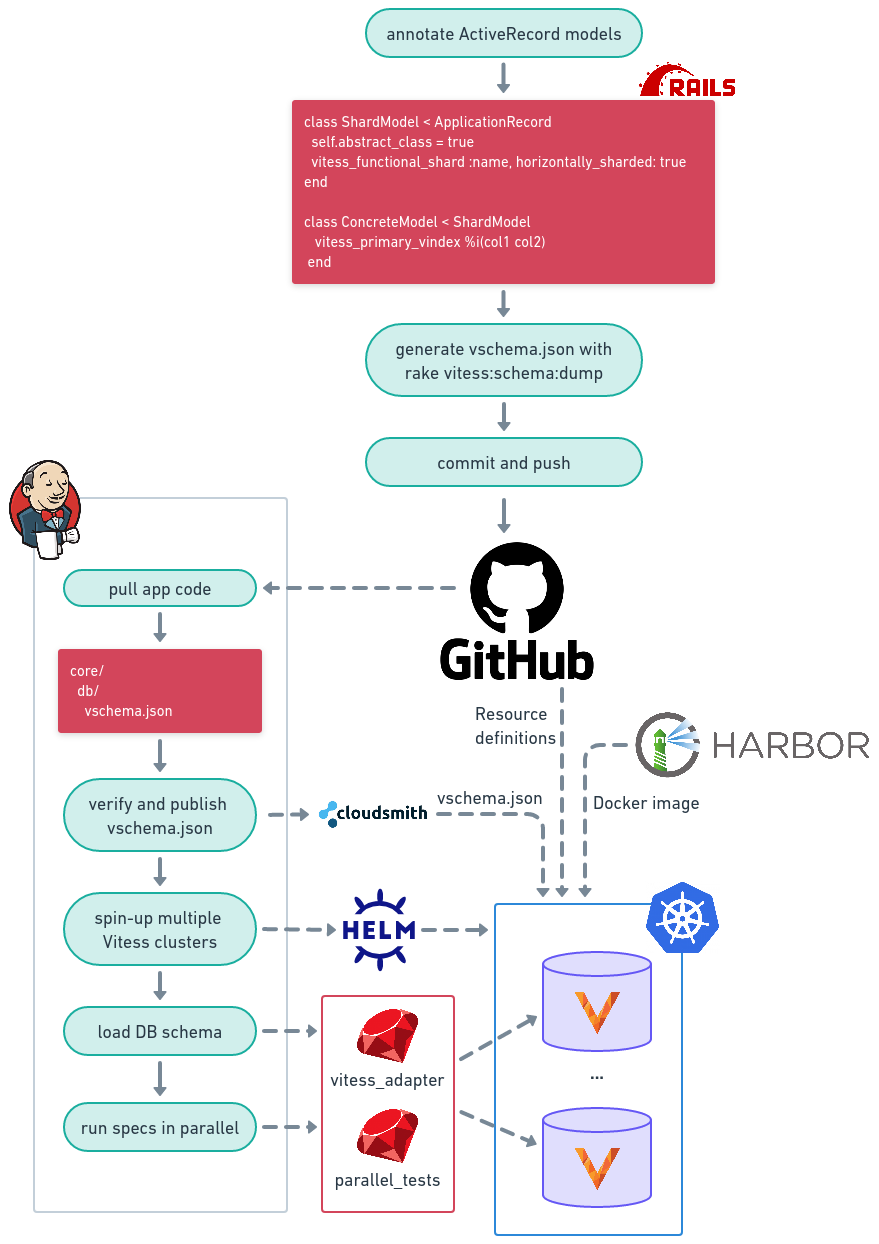
Vitess adapter
Before diving into the test setup details, I have to briefly introduce our Vitess adapter - an internally developed Ruby Gem that does a lot of heavy lifting for applications working with Vitess. Some of the most important features and capabilities added by the adapter are:
-
Support for a mixed setup of multiple ProxySQL clusters and multiple Vitess clusters in a single application. This includes the necessary glue to make our internal online migrations Gem (that uses gh-ost under the hood) work with any such configuration.
-
Instrumentation for sharding annotations together with automatic primary VIndex columns injection into certain queries (functionally quite similar to
query_constraintsof Rails)class ShardModel < ApplicationRecord self.abstract_class = true vitess_functional_shard :name, horizontally_sharded: true end class ConcreteModel < ShardModel vitess_primary_vindex %i(col1 col2) end - Transaction patches to enforce transaction mode and to decorate queries in our query log:
ActiveRecord::Base.transaction(mode: :single, tag: ‘description’) do ... end - Throttler for background jobs to protect Vitess shards from overly aggressive writes that may drive replica lag unacceptably high. It makes use of Vitess tablet throttler interface.
throttler = Vinted::VitessAdapter::Throttler .new(‘name’, [User, Item, Message]) <Foo>.in_batches(of: BATCH_SIZE) do |batch| throttler.wrap do <operations with batch> end end
In the context of testing, a special mention is reserved for the patches of database tasks like db:schema:load to make them work in the case of Vitess. You will hear about this a bit later.
And now we can get back to test setup.
Vitess in a Docker
The very first thing that we needed to do was to make Vitess a thing that we could throw around. We decided to take inspiration from a Vitess local setup example and pack all the important pieces into an “all-in-one” Docker container.
Inside the container, we run etcd, vtctld, vtgate, multiple mysql, mysqlctld and vttablet instances. MySQL instances are semi-shared by VTTablets to limit resource usage.
The Vitess cluster is configured dynamically during container startup. Configuration is driven by an (almost) VSchema JSON that is passed as an argument. Take, for example, the following JSON:
{
"vitess_sequences": {
"tables": {
"table_id_seq": {
"type": "sequence"
}
}
},
"horizontal": {
"sharded": true,
"vindexes": {
"hash": {
"type": "hash"
}
},
"tables": {
"table": {
"autoIncrement": {
"column": "id",
"sequence": "vitess_sequences.table_id_seq"
},
"columnVindexes": [
{
"column": "ref_id",
"name": "hash"
}
]
}
}
},
"main": {
"tables": {}
}
}
It describes a cluster consisting of 3 keyspaces (sharded horizontal and two unsharded ones - vitess_sequences and main) with their appropriate VSchemas from the JSON. All the underlying resources (MySQL instances, VTTablets, etc.) are created automatically.
This pseudo VSchema is auto-generated from correctly annotated ActiveRecord models and is tracked in the same code application repository. The aforementioned Vitess adapter provides a vitess:schema:dump rake task for just that. This task and its companion task vitess:schema:verify also verify that the model annotations are valid: all horizontally sharded models have primary VIndex annotation and they do not contradict each other if multiple models point to the same underlying table.
As already mentioned in the Vitess adapter section, the standard db:schema:load task is patched so that it works in the following manner:
- The database schema from
db/structure.sql(or other files depending on database connection configuration) is split into chunks per keyspace, by consulting their"tables"hashes from VSchema JSON. - Keyspace with empty
"tables"(in our case -main) receives all tables that do not explicitly fall into any other keyspace. In other words, it is a “catch all” keyspace. - The constructed schema load command is executed directly on the primary MySQL instance of each shard of all keyspaces. This shaves 3-5 minutes (for close to 400 tables) as compared to loading schema via VTGate which became excruciatingly slow at some point in time, taking close to one second per table.
- Finally, VSchemas of all unsharded keyspaces are updated by comparing VSchema to the actual tables in MySQL database, and executing appropriate
ALTER VSCHEMA …SQL statements
With these three components (generic Vitess Docker image, VSchema for configuration, and the patched Rails database tasks) we can spin-up and prepare a Vitess cluster for local development or testing of any Vitess-enabled Rails application.
Enter the scale
Having dockerised Vitess running locally on the Jenkins agent machine was sufficient when we were only dealing with a small subset of all specs. But when we realised that we may need to run ALL of the backend tests on Vitess, we had a brand new challenge on our hands.
As you may remember, we were executing around 30,000 RSpec examples, and were relying on the parallel_tests Gem for parallelisation, as otherwise tests would have taken about two hours. So, in a nutshell, we needed to parallelise Vitess tests to a similar degree without exploding our Jenkins agent machines.
Luckily, by that time Vinted was fully into Kubernetes - the major applications, including core itself, were already running on it. So it should come as no surprise that we decided to deploy our Vitess clusters in Kubernetes.
The Kubernetes side of things was rather standard. We used Helm charts to describe our Kubernetes resources, Harbor to store artifacts such as Docker images and Helm charts, and Argo CD to drive delivery pipelines. We define Vitess cluster as Argo CD application and it can be deployed by installing a chart:
helm install \
--values <path to values YAML file> \
--name-template ${instanceName} \
--set fullnameOverride=${instanceName} \
...
As a separate step, we wait for the deployment to finish before starting to use the cluster.
kubectl \
--namespace vitess-docker-ci \
rollout status deployment ${instanceName} --watch
One Vitess cluster on demand is nice, but not nearly enough for our need to execute 30,000 RSpec examples. So we spin up many more (15 at the moment) in parallel. For distributing specs over these clusters, we reuse the same parallel_tests Gem.
When using Rake tasks from this Gem to perform parallel actions, it provides env variable TEST_ENV_NUMBER with a unique batch identifier for each process that can then be used to build a unique database name, for example:
# config/database.yml
test:
database: test_db<%= ENV['TEST_ENV_NUMBER'] %>
In reality this is a tiny bit more complicated, as we add more components to the name (like Jenkins build ID) to make the database name unique across all build jobs running on the same agent.
In Vitess’ case we don’t change the database name, but instead host to point to a different Vitess cluster:
# config/database.yml
test:
host: vitess-<%= ENV['TEST_ENV_NUMBER'] %>.example.com
Once again, it’s more complicated, but the idea is the same: we know how to construct this name from having the base host name and parallel process ID from the TEST_ENV_NUMBER env variable.
Now you may remember that we used the instanceName variable in our cluster deployment helm and kubectl commands. It’s the same host name as the one that we construct in the config/database.yml file. This way, we spin up clusters in advance by naming them precisely, and then they are automagically used for parallel spec batches:
bundle exec rake parallel:load_schema[$parallelism]
bundle exec parallel_test spec -n $parallelism -t rspec
The only missing component is the VSchema that’s needed to correctly configure a new cluster. As mentioned above, this schema file is generated from the ActiveRecord annotations and it’s tracked in the code repository. To make it available to the Vitess cluster that’s being spinned-up, Jenkins agent automatically uploads it to the Cloudsmith repository using its package upload API, and provides its public URL to the cluster as one of the environment variables in the helm install command.
With all these building blocks in place, running all backend tests on Vitess is a fully automatic process. Vitess clusters’ setup is driven by developers appropriately marking ActiveRecord models. This is very convenient when preparing for the next horizontal sharding. Developers mark a functional shard root model as horizontally sharded, add primary VIndex annotations to the descendant models, generate new schema by running rake vitess:schema:dump and push committed changes to a new branch on GitHub. As a result they get all the unsupported queries or changes in behaviour in the build output and can safely work on fixing them in their branch.
Final words
In the engineering world everything is permanently in progress until final decommissioning is completed. Naturally, this holds true for our testing setup. It reflects the progression of our needs and obstacles that we faced on the way, and not the configuration that is the best or the most desirable for us. There are also some potential directions of improvement.
One of the more nagging issues is a rather slow cluster spin-up. Container initialisation and database schema load add up to a few minutes. While not a deal breaker, all of that could go away if we had a pool of pre-spawned clusters. Then a Jenkins build run would only need to checkout a collection of suitable clusters and bring them up to date by executing the latest database migrations.
To conclude, while we had some challenges on the way, this task proved not to be overly complicated. We mostly made use of the technology stack that we already had, which is always a plus in our book. Right now running all backend tests on Vitess is an important component of our CI/CD pipeline that majorly contributes to ensuring the quality of the product that we’re releasing to our members.