Vinted Vitess Voyage: Chapter 3 - The Great Migration
This is the third in a series of chapters sharing our Vitess Voyage story. With the plan ready and wounds healed, we made the move.
The Voyage of 2021
All our CIs were still running on bare MySQL.
“Ain’t nobody got time for that” - Kimberly “Sweet Brown” Wilkins
‘Vinted Autumn’ was coming…
Q1 sandboxes
Sandboxes - the only other environment than production. This was relatively simple since there were only a couple of GB of data. Yet, it took an unacceptably long time due to almost 360 tables and ~500MB of data per portal, because v8 Movetables could only copy or perform VDiff one table at a time. Apparently, one could split start multiple Movetables in parallel and then later merge them into one in order to perform a clean cut-over (Fig. 1). It did require a very careful composition of gargantuan commands, but it did the trick. Everything would break if Errant GTID were to creep in unnoticed.
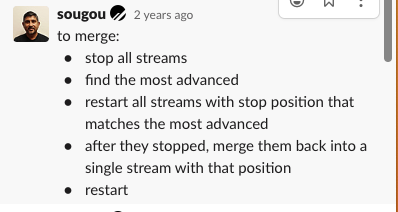
Figure 1: Vitess Movetables split
Q2 first portals
Here came some already vertically sharded portals and first steps on rakes. This is when we had to add dedicated source MySQL replicas to prevent disruption. In addition to this, target primary could no longer keep up with the amount of row changes from multiple Movetables, so we had to limit them too. The throttling feature was not yet available in v8.
Several more interesting issues were detected during the VDiff process. Due to mismatched max_allowed_packet and grpc_max_message_size we received false positive differences. In addition to this, for large enough values WEIGHT_STRING will return NULL from source and destination targets and VDiff would compare NULL vs NULL instead of comparing binary value representations. Vitess support quickly reacted and released a fix.
Even later on, some more issues appeared during other migrations due to feature differences between portals. We had to backport fixes and build our own binaries since we already settled with the v8 version for stability. It was kind of the initiation of the first Vitess code.
Q3 Boss level
With a little bit more confidence built, the only thing left to migrate was the main portal.

Figure 2: Vitess Movetables too slow
Despite all previous divide and conquer optimisations, it was not enough (Fig. 2). Even after devising a number of workarounds, rake hits were sustained. The following list contains most of the tricks employed to pass the Boss level.
1) MySQL 5.7 downgrade
We forgot to pin the MySQL version for Vitess deployments. The bug fix PS-3951: Fix decreasing status counters introduced additional locking which significantly affected transaction performance. Thus, we had to downgrade to 5.7.21-20.
2) Replica optimisations
This was another missing configuration from our old school deployment. We do have different global system variables on primaries and replicas. However, Vitess does not support such functionality. Luckily, vttablet has hooks API. A workaround of a simple cron job triggering a hook on each vttablet every 5 minutes worked like a charm. Based on vttablet type, the hook would set appropriate global variables.
PRIMARYSET GLOBAL sync_binlog=1SET GLOBAL innodb_flush_log_at_trx_commit=1SET GLOBAL innodb_flush_log_at_timeout=1'
REPLICA/RDONLYSET GLOBAL sync_binlog=0SET GLOBAL innodb_flush_log_at_trx_commit=2SET GLOBAL innodb_flush_log_at_timeout=300
3) Secondary index drop & create
This trick is probably one of the best there is. After initial Movetables command execution, we would stop it, drop all secondary indexes and restart workflow. After the data copy phase finished, only then would we recreate dropped indexes. It brought us at least a ~2.5x improvement of copy phase for heaviest tables having at least 2-3 or more secondary indexes.
Example: table of 170GB and 3.2B rows and 3 indexes:
- Normal
Movetables- Copy rate degraded over time due index rebalancing (rows/s every 4h: 38K, 30K, 25K, 23K, 21K, 21K, 18K, 18K, 18K, 17K, 18K)
- Copy time 42h
- Total time 42h
- Secondary indexes dropped
- Copy rate 70K rows/s is constant
- Copy time 13h
- Index add time 4h
- Total time 17h
Feature similar to this trick is now added in v16!
4) More vertical sharding, turn off or refactor
Some vertical shards were already getting too much write load or the use case was bad for Vitess. For example, analytics imports were rewriting whole tables each day. Most jobs like this have moved to other solutions by now. At the time, turning them off temporarily was the only solution.
5) Beware of large GTID sets and source table lists
Movetables workflow itself generated quite a lot of row updates on target primary internal table _vt.vreplication in order to update its position. Row updates contained a GTID set and an encoded source table list. This became especially painful when source shards had very long GTID sets in Executed_Gtid_Set due to a lot of reparents to new hardware. About MySQL56/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx:y-yyyyyyy GTID times 30 would approximately weigh 1000 bytes in size. In addition to this, if 350 tables would be picked for migration, an encoded source table list could weigh about 30K bytes. Such big workflow position updates caused not only high lag on target replicas, but also disks filling up with binary logs. Of course it grew linearly with the count of parallel running Movetables - yet another limitation. Plain manual binary log purges and limiting the workflow count helped. The issue was addressed later by Vitess.
6) Treading dangerous ground
“He who is not courageous enough to take risks will accomplish nothing in life” - Muhammad Ali
Set these at your own calculated risk on target keyspace:
innodb_doublewrite=OFFsync_binlog=0sync_relay_log=0sync_relay_log_info=0innodb_flush_log_at_timeout=1800
Autumn 2021
In the aftermath of the migration, 23 new vertical shards were running our biggest portal. 2x growth was evident both in query traffic and even more in data size.
Ready or not, ‘Vinted Autumn’ still caused a bit of a stir, but afraid we were not. With roads already paved, a couple of more vertical shards were added quickly under our wide belt. Some peculiar things still befell.
1) October 2021 Facebook outage
That caused an almost 15% increase on top of 2x yearly growth, but this time we held it! I’m sure that not every other platform got this lucky.
2) Cache bust
Everyone suffers from this once in a while (Fig. 3).

Figure 3: Cache bust rate
A sudden extreme increase of read load hit some of our primaries multiple times. The good news, vttablet has a query consolidation feature that is designed to protect the underlying database server. When a vttablet receives a query, if an identical query is already in the process of being executed, the query will then wait. As soon as the first query returns from the underlying database, the result is sent to all callers that have been waiting. A high consolidation rate means that there were a lot of simultaneous identical queries, as the cache was partially bypassed. Instead of a thundering herd beating MySQL, vttablet processes got the beating and still did not go down. Go routine counts and query times increased tenfold, causing connection pool fillings too. In a way, Go scheduler had too much work yet again. Still, we kept this feature on to protect MySQL instances and proceeded to redirect load to replicas. Similar experiences were reported too (Fig. 4).

Figure 4: Query consolidation
3) Distributed deadlocks
Random short bursts of query timeouts and connection pool fill ups did slap some transaction heavy shards. The issues resolved themselves on their own. All the symptoms looked similar to the cache bust with high consolidation rates. Little did we know that distributed deadlocks were the culprit too. Luckily, the Vitess community shares their horror stories - Square did encounter the same issue. At least that was clear six months later.
“We still think the tradeoff was worth it: the deadlocks were a small price to pay to shard months earlier and avoid much bigger outages.” - Mike Gershunovsky, Square Inc
4) Space & Lag
One table in particular exhausted all vertical scaling options. Almost 3TB in size and alone it ruled a dedicated shard. Table migrations were impossible long ago, but now even write load was above the threshold for replicas to keep up. It was prime time for horizontal sharding.