Vinted Vitess Voyage: Chapter 2 - The Cunning Plan
This is the second in a series of chapters sharing our Vitess Voyage story. After a busy ‘Vinted Autumn’, the real work took hold.
The Voyage of 2020
By the start of 2020, we had our biggest portal consisting of 11 functional shards with 8TB of data on test cluster. Additionally, we developed a testing environment, query capture and replay tooling. One feature switch away, applications would send all generated and annotated queries to a Kafka topic partitioned by request_id, app_username. Then, queries would be batched by the same partitioning fields and sent to another Kafka topic for storage and replay tests.
Thus, the SRE was tested there!
The basic workflow was to restore the cluster, replay load, adjust and repeat. This is the part where things got more interesting. We were load replaying as quickly as possible which required quite some tuning for Vitess and the replay tooling itself. The Vitess team support was invaluable whenever we hit both unknowns and bugs (Fig. 1). Anyhow, whole replay testing deserves its own blog post.

Figure 1: Vitess support by Sougou
During the year outside of Vinted Autumn’, we upgraded/tested up to v8 with some backports, and the following results were true for us:
1) Additional 1.5 - 2ms overhead on query time
From the test results we saw that the mean time of a query will degrade up to 2 times with Vitess. Peak time average of our non-Vitess queries were in the 1.5-2ms range. Longer running queries were impacted less than faster running ones, which meant that the performance penalty was constant. We saw that our test cluster could handle the load that we had at the time during peak times (190K QPS vs 220K QPS). Vitess components (vtgate, vttablet) actually do have a lot of timing metrics which gave us a lot of hints where the overhead in some parts came from.
2) Additional resource overhead
We could not slim down any shard to a recommended 250GB size and we were far from ready to shard horizontally. It was essential for vttablet, a Vitess component, to be run alongside MySQL without overloading existing hardware. The Vitess documentation and Slack workspace history provided accurate estimates of resource consumption overheads. We observed that vttablet consumed the same amount of CPU as MySQL, which suggested that further vertical sharding would be necessary in the future. Moreover, if combined vttablet and MySQL CPU usage would exceed 50% of the host’s capacity, performance would degrade. Double the CPU usage of vttablet compared to MySQL would indicate that there was an issue with either the query load or vttablet itself. Since Vitess is written in Go, pprof turned out to be an invaluable tool in determining some of those issues. Notably, Go programs would set GOMAXPROCS to match the number of CPU cores on the machine by default, causing the Go scheduler to go mad by stealing all the CPU resources on our high spec machines (64, 96 or 128 CPU cores) (Fig. 2).
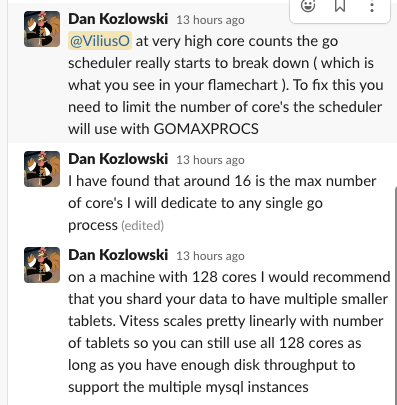
Figure 2: Vitess GOMAXPROCS
So our rules of thumb:
- Per
vtgateinstance- 4 CPU cores
GOMAXPROCS=4
- Per combination of
vttabletandmysqldinstance- All CPU cores available to
mysqldprocess - Half of CPU cores available to
vttabletprocess andGOMAXPROCSset to that number - All connection pools (transaction, stream, query) configured to 2K for
vttabletprocess (if possible use much smaller) - All connection pools prefilling configured to 400 for
vttabletprocess (if possible use much smaller)
- All CPU cores available to
3) Still manual primary switch
Vitess provided orchestrator integration for automatic failover support. However, after some chaos monkeying we ended with split brain situations and decided not to use it. This was OK for us. Practically, we had just one emergency reparent over 3 years. Anything else was manual due to maintenance. Still, Vitess itself provided tools to manually switch primary much easier than our masterfully crafted old school Bash script.
4) If possible, session variables should not be changed
A user might also want to change one of the many different system variables that MySQL exposes. Vitess handles system variables in different ways. Dynamically changing these values might return to bite us in quite unexpected ways: unexpected transaction timeouts, SET queries routed to unavailable replicas… It happened repeatedly in the past for us. So just make sure that the global MySQL variables are set to the same values the application would require and/or use Vitess-aware variables.
5) A big NO to advisory locks
Vitess supports the advisory locking functions and we use them heavily. However, we hold locks for quite a long time while Vitess applies the same transaction timeout for any transaction - 30 seconds by default. Additionally, the reserved connection pool (an extra special transaction pool) was filling up in the vttablet almost instantly. Also, only one vttablet was picked from the alphabetically first keyspace - certainly not scalable. Instead, we reserved a dedicated MySQL cluster for just that. This deserves its own blog post too :) .
6) Tons of query fixing
The obvious elephant in the room. There are compatibility issues where Vitess differs from MySQL. Most of the effort was spent on these:
- Lots of 10k queries to refactor
- Prevent usage of non-Vitess aware session variables due to special behaviour
- Refactor transactions to prevent exceeding 30s timeout
- Refactor queries to fit 30s timeout
- Fix most cross-shard transactions to at least self heal
- Remove cross-shard joins
7) Other work
In order to really migrate to Vitess, we had other prerequisites:
- Dockerised Vitess for development and CI
- Database adapter for Rails applications
- Schema migration mechanism support for Vitess and multiple keyspaces
- Cross-shard join and transaction monitoring
- Primary and replica query handling
- Database and table introspection
- HAProxy balancer in front of
vtgates
Autumn 2020
In the beginning of the second wave of the Covid-19 pandemic, we were getting our “bones” broken and performing the last old school vertical sharding.
We had to compromise on some tasks and push forward since we had many portals with hundreds of tables - each being bigger than the other.
Migration workflow designed
After surviving yet another ‘Vinted Autumn’ and more extensive testing, we muscled up our Vitess skills and layed down the grand migration plan. It was based on documented Movetables functionality. Each functional shard was migrated this way with the help of migration plan generation scripts.
The following 5-step example briefly illustrates how we migrate a single table tableB to a new vertical shard.
Unmanaged
vttabletis avttabletprocess which connects to an already existing MySQL server setup.
Managed
vttabletis avttabletprocess which connects to Vitess managed MySQL server setup. Usually it is Vitessmysqlctldprocess which managesmysqld.
1) Deploy & Copy data
- Prepare all applications for a new vertical shard just like with old school vertical sharding.
- Lock table migrations for functional shards.
- Provision unsharded keyspace
db2in Vitess. - Start unmanaged
vttabletprocesses for each source MySQL server as keyspacedb1 - Provision additional source MySQL server with
RDONLYvttablettype. This is going to speed up data copying during migration and prevent any disruptions. - Start
Movetablesworkflow to migrate tables from keyspacedb1todb2. - Perform
VDiffto ensure there are no missing/extra/unmatched rows between source and target keyspaces.
2) Canary release
Switching to Vitess might reveal hidden issues, so we make sure to minimise the blast radius. Canary release gives us an option to revert and have time to fix our applications.
- Switch analytics apps fully to Vitess for functional shard. All queries would be served by
db1unmanagedRDONLYvttablet. - Switch only some instances of asynchronous apps to Vitess.
- Switch only some instances of main apps to Vitess.
3) Full release
- Fully switch all applications to Vitess for functional shard
- Run at least 24h to make sure nothing breaks.
- Switch
RDONLYtraffic fromdb1todb2keyspace. - Switch
REPLICAtraffic fromdb1todb2keyspace.
4) Final cut-over
The major difference from our old school vertical sharding final switch - it is reversible.
- Switch
PRIMARYtraffic fromdb1todb2keyspace. - Ensure reverse
VReplicationwas created after the traffic switch. - Change applications to use
db2keyspace for functional shard.
5) Complete
- Perform
Movetablescompletion. We always kept the renamed source table for some time before dropping it. - Celebrate.